




















新闻自动写作若干技术研究【2】
如果 t时刻隐藏层状态依赖于 t 之前所有时刻,梯度需要通过中间所有隐藏层回传,如图2-2所示,这会形成一个很深的求导链:
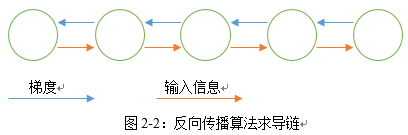
在许多实际问题中,t时刻可能只依赖之前的有限时刻, 除此之外,简单的RNN模型无法辨别不同时间的信息的是否有价值。RNNs的很多变种就是为了解决这些问题。
2.2.2 RNNs扩展和改进模型
近些年,研究者们已经提出了多种方法改进vanilla RNN模型的缺点,大致可以分为两类:一类是以新的方法改善或者代替传统的SGD方法,如Bengio[5]提出的clip gradient;另一种则是设计更加精密的recurrent unit,如LSTM,GRU。本节主要介绍常见的改进的RNNs模型包括LSTM,GRU。
2.2.2.1 Long Short-term Memory Networks
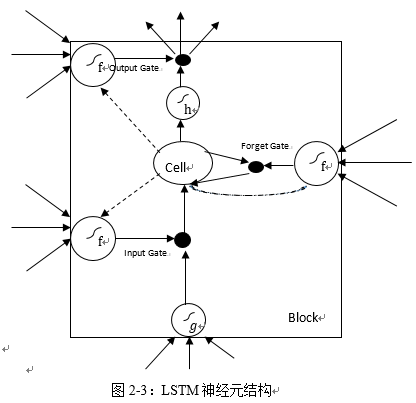
由于Vanilla RNN 具有梯度消失问题,对长关系的依赖的建模能力不够强大,很长的时刻以前的输入,对现在的网络影响非常小,后向传播时那些梯度,也很难影响很早以前的输入,就会出现梯度消失的问题。而 LSTM[6] 通过构建一些门(Gate),让网络能记住那些非常重要的信息,这个核心的结构,就是 cell state。LSTM也有许多变种,本文只介绍基本的LSTM模型。
LSTM和传统的RNN结构基本相同,不同点在于隐藏单元的构建,隐藏单元主要由三个门构成,分别对应不用的功能,如图xxx,公式中h_t表示神经元的输出值,W表示权重。

2.2.2.2 Gated Recurrent Units

2.3语言模型用于文本生成
语言模型是一个概率分布模型,简单来说,就是用来计算一个句子的概率的模型,是自然语言处理领域里一个重要的基础模型。它的基本任务是给定一条文字序列,判定在给定之前字的情况下,当前字出现的概率,用于评估一条文字序列是通顺句子的概率,语言模型在训练的过程中可以得到副产物词向量,可以作为很多NLP任务的基础,词向量是单词子在向量空间的表示,和传统的one-hot相比,词向量表示法具有以下优点:
将词嵌入实向量空间,对抗维数灾难。
一个n 维向量,如果每个维度仅能取 0、1 两个值,这个n维向量只能编码2^n种信息。如果每个维度能够在整个实数域 R 取值,n位实向量可以编码无穷种信息。嵌入实向量空间使用更少的维度,编码更丰富的信息。
词语,短语,句子,篇章等等自然语言信息都可以嵌入同一个实向量空间,得到统一的表达形式。比起 one-hot 向量空间,嵌入了语义信息的实向量空间紧凑了很多,但依然存在很多未知的空洞,很难知道,空间中的每一个点到底表示了什么。
更好地刻画语义信息,相近意义的词语、短语、句子,在向量空间中有着相近的位置,这个空间就蕴含了语义信息,这一点是可以做到的。
词向量的训练可以使用Word2Vec[8],Word2Vec包含两种训练方法:Continuous Bag of Words(CBOW)和Skip-gram。CBOW的目标是根据上下文来预测当前词语的概率。Skip-gram刚好相反,根据当前词语来预测上下文的概率。这两种方法都利用人工神经网络作为它们的分类算法。起初,每个单词都是一个随机N维向量。训练时,该算法利用CBOW或者Skip-gram的方法获得了每个单词的最优向量。
 |  |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
