




















新闻自动写作若干技术研究【3】
这个思想很多学者已经有所尝试,Andrej Karpath[9]使用莎士比亚的作品作为训练集,生成具有莎士比亚风格的文章,布尔诺科技大学Tomas Mikolov[11]等人提出一种新的基于Recurrent Neuarl Networks的语言模型(RNN LM),模型如图2-5,使用最简单的RNN模型,用context来预测下一个目标词。 网络有三层,输入层x,隐藏层s(context layer),输出层y。在时刻t的输入为x(t),隐藏层输出为s(t),输出层输出y(t)。输入是当前词(one-hot编码,词表长度V)和t-1时刻的隐藏层输出s(t-1)的联合,输出是词表长度的预测词概率,不同层的计算方法是:
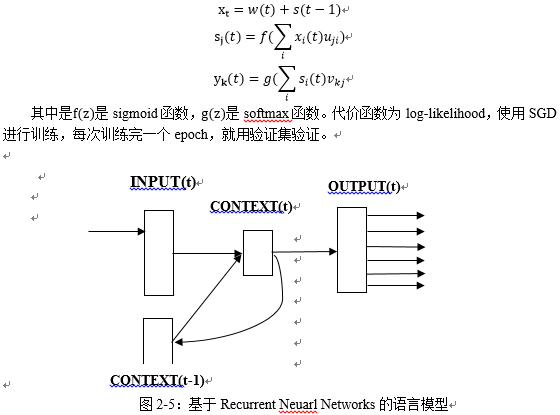
总结来说,语言模型生成文本的输入通常是词的序列,输出是预测得到的词的序列,对应到新闻文本的生成,给出某一主题的新闻或者具有相似结构的新闻作为训练数据集,得到一个可以写出类似主题的新闻模型,基本如下:
1. 预处理,得到语料,如人民网新闻数据,对语料进行清洗,去除无用标识,对新闻
进行分词,分句。
2. 使用one-hot对文本进行数值化处理,将文本转化为矩阵
3. 训练语言模型 ,得到词向量
4. 以词向量序列作为输入,使用RNN模型,计算输入序列在下一时刻的编码,一般使用LSTM,GRU或者是深层RNN模型可以得到对序列更好的编码。
5.输出层使用softmax,以前一层激活函数的输出作为输入,预测下一个可能的词的概率。
6.重复以上过程,直到句子结束。
从贝叶斯角度来说,训练过程是一个最大似然估计的过程,最大化下一个词的概率。
2.3 深度生成模型用于文本生成
文本生成常用的生成模型主要是变分自动编码[10](Variational Autoencoder ,VAE),变分自动编码器比起传统自动编码器,对于隐变量层有限制条件,使得隐变量层的结构更加紧凑。同时,这个限制条件的引入使得变分自动编码器实际上成为一种生成模型,可以从隐变量空间中根据先验分布采样一个点,然后由该点演化生成为一个目标输出。变分自动编码器优化的目标方程如下:
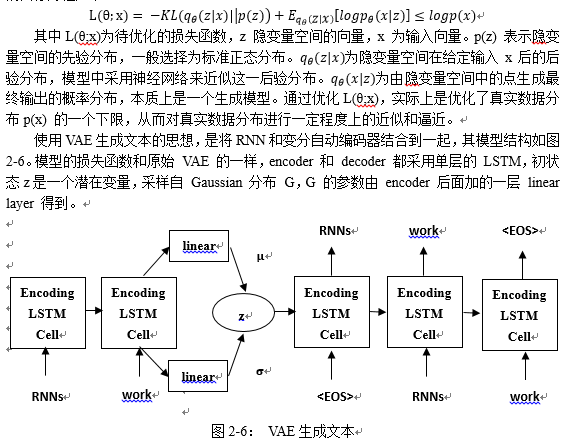
该模型的训练过程为:对于一句输入的纯文本,左侧RNN依次读入每一个单词,并输出一个当前的状态。当最后一个单词读入完毕后,最后输出的这个状态被输入到多层感知机linear的模型中,输出两个参数μ,σ这两个参数即为q_θ (z│x) (采用高斯分布)中的两个对应参数。随即模型从q_θ (z│x)中随即采样出一个点z, 这个z 向量将作为右侧RNN的初始状态向量,参与到最终输出文本的生成中。
模型在训练过程中,输入文本和输出文本是相同的,在测试过程中,则根据标准正态分布采样出一个点z, 然后再由训练好的右侧RNN生成文本。
模型很简单,但实际训练时有一个很严重的问题:KL 会迅速降到0,后验失效了。原因在于,由于 RNN-based 的 decoder 有着非常强的 modeling power,导致 decoder 不依赖 encoder 提供的z ,模型退化成 RNNLM。常见的解决方法是KL cost annealing[12] 和 Word dropout[13]。
三、难点与思考
上一章使用的文本生成技术,存在一些难以解决的问题,主要表现在两方面:
一方面,神经网络对输入信息往往会有一定的要求:我们通常希望输入信息足够的原始,但却要包含了足够多和最终任务有关的信息,这个要求对图像和语音来说相对容易实现。图像和语音是一类原始的感知输入信号,输入的微小改变并不影响本来意义,可以连续变化,这对优化算法帮助很大,而自然语言是人类创造出的、对所认知世界的二次编码,是离散变化的,语言之上承载了人们对世界的认知,常识,推理等等。至今还没有找到合适的方式对这一类信息进行编码,我们的目标是找到的编码要足够原始,同时对语言所描述信息的损失足够小。
另一方面,模型虽然可以根据语料生成对应的文本内容,但是文本生成的质量无法保证,人类在评价一篇新闻的时候,常常会考虑语句的通顺程度,语言的表达是否清晰或者新闻内容是否真实等,但模型的优化目标都是基于词的,真正的文本生成任务最终的目标应该是衡量整句话的质量,由于训练和生成的文本质量之间没有关联,训练时总是根据正确的当前词预测下一个词,而生成时只能引用训练好的模型生成词,一旦生成错误的词,内容会越来越错,导致生成错误的新闻。
四、总结与展望
文本生成技术在机器翻译、句子生成、对话生成等方面已经取得了成功,在新闻的自动生成上还没有相对成熟的技术方案,技术上,生成多句话,到一段话,再到一篇新闻,常常涉及到很多复杂的语言理解,记忆,推理等等,这些都是目前远未解决的难题,目前可行的方法还是利用现有的技术做更多的尝试,尝试新的词表示方法,一体化地学习词、句子的表示,更好的建模了句子的上下文,包括源序列和目标序列的上下文以及解码编码中的上下文。
 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
