 ����������
����������

��2012��ȡ��������������Ľ�������������
2012��ȡ��������������Ľ���������10��30�ս����������ʵ��ѧ�����ѧԺ����������ͬѧ����Ʒ������������Ϣ�����е����ķִ��㷨�о���������������㼼��������Ƚ�������������ȫ�ģ�
һ���о���Ŀ��ʵ����
��������Ϊ���ʻ������������ۺ�������ý��֮һ������Ϣ��ʱЧ�ѿ�ҲԽ��Խ�ߡ�����WEB 3.0ʱ���ĵ������Ż���վ����ý���Ѿ������ǻ��������ݵ���Ҫ��Դ��SNSƽ̨���������ͣ���̳����������ÿ�������������ݣ�UGC������ÿ�յ��ȵ㣬����Ҳ�̺������С�����������ӵĺ������ݣ���δӺ����������ھ���ȵ����⣬�Ӷ�Ѹ�ٰ����ȵ㶯̬���������飬Ҳ��Ϊ�������dz������Լ�ؽ����������⡣
ΪӦ�Ի������ĺ������ݴ������Ƽ���Ӧ�˶������������е��ƿ�ܣ��������������е�����������ȡ���������������������ռ�����Ⱥ���У������Ƽ��㼼���������ݵij�ȡ���ھ���˵�Ƽ����Ѿ������������㺣�����ݸ����������������ݴ洢�Լ����㷽�����ս����������֪�����������ĵ���Ϣ������Ҫ�����õ����ݴ�������������һ���dz���Ҫ�ķ���������ĵ���Ȼ���Դ���������
����֪�����������������ط�������ϵͳ���㷨�ǻ���WEB�ı��ھ�һЩ������ģ�����㷨����TF-IDFģ�ͣ����������Apriori�㷨���ලѧϰ��SVM�㷨�ȵȡ�Ȼ����Щ�㷨�����������ı��ھ���Ⱦ�����������һ���������ĵķִ�ģ�飬�������ķִ���Ϊ������������������Ļ������ߣ���ɫʮ����Ҫ��
������֪��������Ӣ����д��������ͬ���ڣ�Ӣ���Դ�Ϊ��λ������ÿ����֮���пո����������Ӣ�ķִʷdz�����������������Ϊ��λ�������֮���ո��������ķִ�Ҫ���Լ�������һ������
������ữ�����е����ķִ��㷨
��ǰ�����������������,���������dz����졣һ��������Ż���վ���ټ��ҵ��г������������û�����Ϣ��ȡ��ȷ�Ⱥ��ȶȵ�Ҫ���ս��ϸ�Ϳ��̣�����һ���棬���ڿͻ�ҵ����������ʷ���������µĺ���ҵ�����ݣ��������������Ƶ������ʲ������ӣ��Էִʼ���������µ���ս��
��ữ����һֱ����������ע���ص����⣬�ִʼ���Ҳ��Ϊ��������������ϵͳ�е���Ҫ��ɲ��֡������������ʵ��������ڶ����ŵ����ݵķִʵ�����Ҫ�������¼������⣺�ִ��������⣬δ��¼�ʵĴ������Լ�רҵ�ִʴʵ�Ĺ�������������ữ�����о��������һЩ�����������ʣ��磺��������γ�ɳ��ί��֯���������������ع�������ִ����̬���ȣ����С�������������ع��ӡ���Щ�ʿ������������еĴʿ��в����ڣ����ѱ��зֳ��������Ǹ����������о����ۣ����������������ữ�������ŵķ�������������Ե�����������˼��ִַ��㷨��������ԭ����������ȷ������������Ӧ�õ��ִ��㷨��Ҳ����ϸ������ͨ���о���������Ϊ�����������Ʒ�ģ�ͣ�HMM���ĸĽ�ģ�Ͷ����������Ʒ�ģ�ͣ�CHMM���ڷִ��㷨�ϸ�Ϊ��ɫ�����ʺ�Ϊ��������ϵͳ�ṩ����
���ͬʱ�������������������ϵͳ��������Ϊ����Ԥ������Ĵ�Ӧ�������ʶ��ʻ������ݴʡ�����һЩ�����磺�����ǡ������ʡ��ġ��ȿ��Խ��й��ˡ��������ǵķִ�ģ�����ͨ�����Թ��ˣ������йؼ�����ȡ��ʹ���ݴʵ���������ȷ��
������ˣ���������ϵͳ�еĴʶ���Ϊ�´ʣ������ṩ�´����ӹ��ܣ��Ա�ʹ�ִ�Ч������ȷ�����巽�����ڵ�������������
�������о���ͬʱ�����ǶԱ�������Ķ����������Ʒ�ģ���㷨����ʵ�֣�������˴��Թ����������´ʵĹ��ܣ�ʹ�ִ�ȡ���˽Ϻõ�Ч�����Ӷ�ʹ���۽����ʵ�ʣ�Ϊ�������ķִʼ������Ż��ṩ�˿ɿ��ķ�����
���������ѵ����
������������ý�������ص�ͺ�����ữ���ŵ��ص��Լ���������ϵͳ���������dz����ܽ������������ؽ������ķִ����⣺
3.1���������壺
���ִ����ִ�AJB���������AJ��JBͬʱΪ��(A��J��B�ֱ�Ϊ���ִ�)����ô�ִ�AJB�������������з����塣���磺����������δ���ġ���Ӧ�÷ֳɡ���飯�ģ��ͣ���δ����飯�ġ���Ҳ���Էֳɡ���飯�ģ����У�δ����飯�ġ���
3.2��������壺
������ִ�AB����A��B��ABͬʱΪ��,��ôAB������������з����塣���磺�������ŵİ��֡��еġ����֡�����һ���ʣ�������̧�������ġ����֡��ͱ����
3.3δ��¼��ʶ��
δ��¼����������ǰ����ִʽ������,���������������зֵ��Ѷ�,�������صظ��������ڴʵ���ȷ�з�,�Ӷ����ؽ����˴ʷ����������������ӷ�������ȷ�ʡ�
�ں���������ŵ��ı����У�δ��¼��������Ϊ��Ҫ��δ��¼����Ҫ�������¼������棺�й���������������������������´ʡ�
���ԣ���������ķ���������Ҫ�ܽϺý���������⣬��������������ں�����ữ���ŵĴ����Լ���������ļ�⡣������Ϊ����HMM�Ľ�ģ���㷨���ԽϺõ�Ϊ����������ִʼ������⣬��Ϊ��������ϵͳ�ṩ���ʷ���
�ġ����ķִ��㷨��ƣ�
���ķִʷ����ɴ��Է�Ϊ������:��1���ǻ�������ѧ֪ʶ�Ĺ���,��:������̬�����ƥ�䡢�����зַ������Լ��ۺ������ƥ��������зֵ�N-���·����������2���ǻ��ڴ��ģ���Ͽ�Ļ���ѧϰ����,����ĿǰӦ�ñȽϹ㷺��Ч���ϺõĽ���������õ���ͳ��ģ����NԪ����ģ�͡��ŵ�-����ģ�͡�����������������Ʒ�ģ�͵ȡ�����������������������࣬����ÿ�������ʲ�����������������Ϊ��е�ִ����ͳ��ģ�ͷ���������ƣ��������м����˹���Ԥ�����˹����������ϵķ��������Դﵽ�ȽϺõ�Ч����
4.1�����ַ���ƥ����㷨
�����ַ���ƥ��ķִʷ����ֳ�Ϊ��е�ִʷ��������ķִʲ��Լ�˵���ǽ����з��ִ���ִʴʵ��еĴʽ���ƥ�䣬����ܹ��ڷִʴʵ����ҵ����ִ���������з֣��������з֡������ַ���ƥ��ķִʷ�����Ҫ���������ƥ���㷨(Forward MM, FMM)���������ƥ���㷨(Backward MM, BMM)��˫�����ƥ���㷨��Bi-directional MM������Сƥ���㷨��Minimum Matching����
������������ƥ�䷨��FMM����Ϊ��е�ִʷ��Ĵ��������������ϸ���ܣ�����ͼ��ͼ3-1��ʾ��
1.��ʼ�����з��ִ�S1,������ִ�S2��S2Ϊ�գ�
2.�ҳ��ִʴʵ�����Ĵ���������ô����������ָ���ΪI��
3.ȡ�������ı���ǰ�ַ���S1�е�I������Ϊƥ���ֶΣ����ҷִʴʵ䡣���ʵ�����������һ��I�ִʣ���ƥ��ɹ�����ƥ��ɹ��Ĵ�W����S2���ڸ�ƥ���ֶκ��һ���зֱ�־��Ȼ����������������ľ��ӣ�
4.����ִʴʵ��в��Ҳ���������һ��I�ִʣ���ƥ��ʧ�ܣ�
5.�ϲ��е�ƥ���ֶ�ȥ�����һ�����֣�I--��
6.�ظ�����3-5��ֱ���ܹ��ڴʵ��н���ƥ�䣬����ƥ����ִ��ɹ��з֣�
7.�����зֽ��������S2��
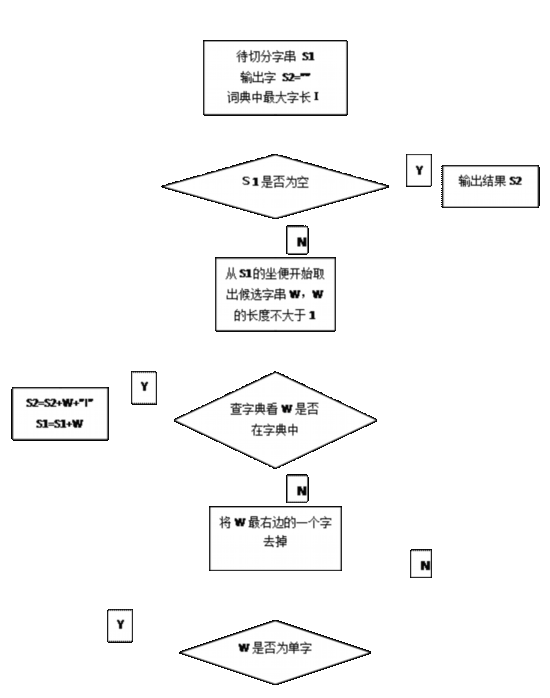
ͼ4-1
�������ƥ�䷨���ŵ��������ʵ�ֶ��ҷִ��ٶ�Ҳ�ȽϿ죬���ǶԽ���������������û���ر�õĽ���취����Ϊ��ֻ�Ǹ��ݴʵ���л�е���з֡���ͳ�ƣ��ڴʵ��걸��û���κ�����֪ʶ�������£������з���1/169�������и��걸�Ĵʵ��Dz�����ʵ�ֵģ��÷�������������ʹ�ã������������������ʹ�á�
���ǿ��Խ���һ�������������Ľ���е�ִʵ����ܣ����磺���������ӡ��ϡ������ơ��������������Ρ�ʱҪ�ѡ��ᡱҪ�����г����������ԶԷִ�������һ�������ϵ�������������ά��һ�Ų������ɴʵ��ֱ�������ΰ�����ȡ�����ά���������ı��ķ����Ứ�Ѵ�����������Դ��������Ҫ���ϸ��¹������ܻ���ֹ���ij�ͻ��
4.2���ڴ��ģ���Ͽ��ͳ��ģ���㷨�о���
�ڷִ��㷨���о��У�����ͳ�Ƶķִʷ����ͻ�е�ִʷ������ǽ��洦���쵼��λ��ʱ�����գ�����ͳ�Ƶķִʷ���Խ��Խ�ܵ�ѧ�ߵ�����������ͳ�Ƶķִʷ�������������������ģʽ��
һ�����ú���֮���Ϲ�ϵ�Ľ��̶ܳ����ж���Щ�ַ���Ӧ�ý�ϳɴʡ�����ͳ�Ƶķ��������ڷִʹ���������Դʵ�������������ȶ����ֵ���ϣ�������������У����ڵ���ͬʱ���ֵĴ���Խ�࣬��Խ�п��ܹ���һ���ʡ�������������ڹ��ֵ�Ƶ�ʻ�����ܹ��Ϻõķ�ӳ�ɴʵĿ��Ŷȡ����Զ����������ڹ��ֵĸ����ֵ���ϵ�Ƶ�Ƚ���ͳ�ƣ��������ǵĻ�����Ϣ�����ַ����������Dz���ʵ䣬�Դʵ�����¼�Ĵʺ�δ��¼�������ƵĽⷨ����Ҳ����Чʵ�ֶԳ��ڶ��ֵĴʵ����촦����
����ģʽ����ԭ����ͨ�������������ַ����ķֲ���ǿ�ȣ��������ظ����ֵĸ��ʺͻ������Դ���Ϊ���ַ����Ƿ�Ӧ���ֳɴʵ�һ�䡣�����֮������ģʽ��Ѱ������������ܳɴʵ��ַ�����ģʽ�����������ڶԴʵ�����¼��δ��¼�Ĵʾ�ʹ�á����Ҷ���ͬһ�ַ������ڲ�ͬ�������У����Ų�ͬ�ķֲ�ǿ�ȣ���Ȼ���Եõ���ͬ�ķ���������������������ַ�����ȫ���Դﵽ����������������Ϸ��������
�����Զ�Ԫ��Bi-Gram�Ļ���ԭ��Ϊ����˵��������������������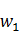 ,
,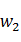 ��ͳ�������Ͽ��д�������ǡ��������P(,)�����Dz���һ����Ķ�ά�����ٶ���һ�����ӵĻ��ַ����ĵ÷�ΪP(?,)��P(, )������P(
��ͳ�������Ͽ��д�������ǡ��������P(,)�����Dz���һ����Ķ�ά�����ٶ���һ�����ӵĻ��ַ����ĵ÷�ΪP(?,)��P(, )������P(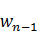 ,
,  )������, , ��, ���α�ʾ�ֳ��Ĵʡ����ö�̬�滮����÷���ߵķִʷ�����
)������, , ��, ���α�ʾ�ֳ��Ĵʡ����ö�̬�滮����÷���ߵķִʷ�����
4.2.1�������Ʒ�ģ�ͣ�HMM��
4.2.1.1����ԭ��������
�������ɷ�ģ�����������ɷ�ģ�͵Ļ����Ϸ�չ�����ģ�����Ϊ�˽�����ǹ۲���¼�������������״̬һһ��Ӧ��ֻ��ͨ��һ���ĸ��ʷֲ�����ϵ�����������ġ�HMM��һ��˫��������̣�һ���Ǿ���һ��״̬���������ɷ��������ǻ�����������̣�������״̬��ת�ƣ���һ�������������״̬�۲�ֵ֮���ͳ�ƶ�Ӧ��ϵ������ģ�͵�״̬ת�������Dz��ɹ۲�ģ������֮Ϊ�����������ɷ�ģ�͡�һ��HMM������һ����Ԫ��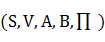 ����ʾ�����У�
����ʾ�����У�
��1�� S����һ��״̬�ļ��ϣ�S={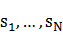 }�����е�״̬��ΪN������
}�����е�״̬��ΪN������ ����ʾtʱ�̵�״̬��
����ʾtʱ�̵�״̬��
��2�� V��ʾһ��ɹ۲���ŵļ��ϣ�V={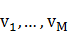 }��M�Ǵ�ÿһ��״̬��������IJ�ͬ�۲�ֵ����Ŀ��
}��M�Ǵ�ÿһ��״̬��������IJ�ͬ�۲�ֵ����Ŀ��
��3�� A����״̬ת�Ƹ��ʾ���A={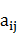 }������
}������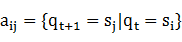 ��
�� �����Ǹ�N��N�еľ�����ʾ��״̬
�����Ǹ�N��N�еľ�����ʾ��״̬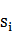 ת�Ƶ�״̬
ת�Ƶ�״̬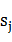 �ĸ��ʡ�
�ĸ��ʡ�
��4�� B��ʾ�ɹ۲���ŵĸ��ʷֲ��� }��
}��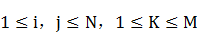 ��ʾ��״̬����۲����
��ʾ��״̬����۲����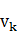 �ĸ��ʡ�
�ĸ��ʡ�
��5�� 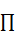 ��ʾ��ʼ״̬�ĸ��ʷֲ���
��ʾ��ʼ״̬�ĸ��ʷֲ���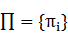 ������
������ ������ʾ��ʱ��1ѡ��ij��״̬�ĸ��ʡ�
������ʾ��ʱ��1ѡ��ij��״̬�ĸ��ʡ�
һ��ȷ�����������ɷ�ģ�ͣ���״̬����ÿ��״̬��������Ĺ۲�ֵ����Ŀ���ǿ���ȷ���ģ���˿����ã�A��B��������ʾģ�͵IJ��������У�����A���������ɷ��������������Ϊ״̬���У���ΪQ����ʾ��t��ת�Ƶ�Դ״̬��B������������̣����������Ϊ�۲�ֵ���У���ΪO����ʾ��t��ת�Ƶ������
4.2.1.2����HMMģ�͵ķִʲ��ԣ�
���ķִʵ�NԪͳ��ģ����,���ź�Դ����Ϊ�����ź�Դ,Ҳ���Dz����˶�Ԫͳ��ģ�͡�����ʱ��Markovģ���е�״̬�����ǹ۲첻���ġ�����Ӧ��ȷ���зִʵ����о��Ǵ�����ģ�͵���ʵ����,�����ִʵ��ı����Ǵ��������·����Ĺ۲�ֵ�����ڶ�Ԫͳ��ģ����,���ķִʵĹ��̾�ת����֪����ģ�۲�ֵ(�ı�)�������ʵ���е�ֵ(�ִʽ��)����¼Markov��Դ�����Ĵʵ�����C��ij�����ִܷʽ��ΪW=(,��,)��W��Ӧ�Ĵʵ���״̬����C=(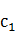 ,��,
,��, )������ѡ�����ŵ���״̬������Ϊ���ǵķִʽ��W*:
)������ѡ�����ŵ���״̬������Ϊ���ǵķִʽ��W*:
��W#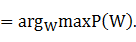 4-1-1
4-1-1
���ñ�Ҷ˹��ʽ����չ�����õ�
W#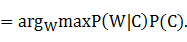
�������״̬��������Ϊ�۲�ֵ������һ��HMMչ������
W#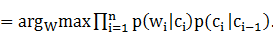 4-1-2
4-1-2
�����У� Ϊ���ӵĿ�ʼ���BEG����ͬ��
Ϊ���ӵĿ�ʼ���BEG����ͬ��
Ϊ���㷽�㣬���ø����������㣬��
W#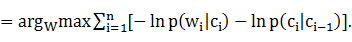 4-1-3
4-1-3
��W*����������ת��Ϊ����������Сֵ��������������Ĵʵ�Ĵ�,p( |
|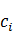 )=1�ִʹ�����ֻ����δ¼�Ǵʵ�p(|)ֵ��
)=1�ִʹ�����ֻ����δ¼�Ǵʵ�p(|)ֵ��
4.2.2���������ģ��(CRF)
4.2.2.1 CRF����ԭ������
���������ģ�ͣ�Conditiional Random Fields,CRFs����һ�ֽ����зֺͱ�ע�������ݸ���ģ�͵Ŀ�ܣ��������������ķ�ʽ�ۺ�ʹ�ø��ֻ���Ӱ������������������������ģ�ͺ�HMMģ�͵��ص㣬�ر��˴�ͳHMM������������������IJ����MEMM��ģ���еı�עƫ�����⡣
CRF��һ������ͼģ�ͣ�����ָ���Ľڵ�����ֵ���ܹ�����ָ���Ľڵ����ֵ�ϵ��������ʡ���ѵ��Ŀ����ʹ���������������������CRF�г������ض�ͼ�ṹ֮һ��������ָ��������ڵ�˳�����Ӷ��ɡ�����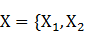 ,��..,
,��..,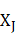 }����Ϊ����������۲����У�������ͼģ����t������ڵ��ϵ�ֵ����һ�����Ĵ����У�������
}����Ϊ����������۲����У�������ͼģ����t������ڵ��ϵ�ֵ����һ�����Ĵ����У�������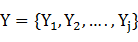 Ϊһ��������x��ȵ�״̬���У�������ͼ��t������ڵ��ϵ�ֵ������
Ϊһ��������x��ȵ�״̬���У�������ͼ��t������ڵ��ϵ�ֵ������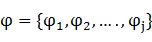 ��������CRF�Ѹ�����������x�õ���״̬����y���������ʶ���Ϊ��
��������CRF�Ѹ�����������x�õ���״̬����y���������ʶ���Ϊ��
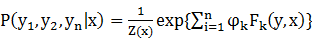 4-2-1
4-2-1
Z(x)��һ���������ӣ�ʹ���ڸ��������ϵ����п��ܵ�״̬���еĸ���֮��Ϊ1��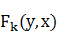 ��ʾһ������������ͨ��ȡ����ֵ��
��ʾһ������������ͨ��ȡ����ֵ��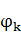 ��ѵ���еõ��ģ���ÿ������
��ѵ���еõ��ģ���ÿ������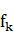 ��ص�Ȩ�ز���������ȡֵ��ӳ�������������������¼������Ŀ����ԡ�
��ص�Ȩ�ز���������ȡֵ��ӳ�������������������¼������Ŀ����ԡ�
4.2.2.2.CRF�ִʲ���
һ������������ִʣ����ǽ����↑ʼ�ͽ������ֱ�dz��������ܶ�һ��������ɷִʣ�����ʹ���������B (��ʼ)��E(����)�Ծ��ӽ��д������磺��������������ֵ������B��E��B��B��E��BֵE, ���������ȷ���ִʽ������ȷ�ˡ�
��������ҵ���õı�ǽ����֪������ñ�ǵķ�ʽ����ִʣ���ô��ôΪһ�������ҵ�һ����õı�������أ�CRFΪ�����������ṩ��һ�����������������������(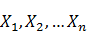 )(���ڷִʣ������Ǹ�����)��������������������� ij���������(
)(���ڷִʣ������Ǹ�����)��������������������� ij���������(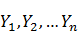 )�ĸ��ʼ�ֵ��
)�ĸ��ʼ�ֵ��
����������̣�
CRF�Ĺ�ʽ��
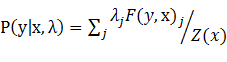 4-2-2
4-2-2
��ʹ��4��ǣ�B-��ʼ��O-�����ɴʣ�M-�����м���֣�E-������������һԪ������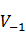 ��ǰ�ֵ�ǰһ���֣�
��ǰ�ֵ�ǰһ���֣�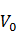 ��ǰ�֣�
��ǰ�֣�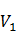 ��ǰ�ֵĺ�һ���ֶ�Ԫ����������Ǽ��ת��������
��ǰ�ֵĺ�һ���ֶ�Ԫ����������Ǽ��ת��������
���磺
�� �� �� �� �� �� ֵ
B BBBBBB
O OOOOOO
M MMMMMM
E EEEEEE
����Viterbe�����㷨�����������ɱ����ɵ�����������һ�����ŵ�·��������ÿһ�е�ÿһ����ǣ����Ƕ�Ҫ���㵽��ñ�ǵķ����������������������ɣ���������һԪ����Ȩ��W����ǰ��һ���ֱ�ǵ�·������PreScore��ǰ��һ���ֱ�ǵ���ǰ���ת������Ȩ��TransW��
1. �����һ�еķ���(score),���ڣ�������˵������Ҫ�� B,O,M,E��Score����Ϊ�ǵ�һ�У�����PreSocre��TransW����0���Ͳ��ü��㣬ֻ��Ҫ�����Լ���һԪ������Ȩ�أ����ڱ�ǣ�B�����Ǽ�������Score����ΪS1B= B=w(nul��,B)+w(��,B)+w(��,B,��)��
B=w(nul��,B)+w(��,B)+w(��,B,��)��
��Щ��������˼�ǣ�(null����B)����ǰ��Ϊ�����ΪB��ǰ��һ����Ϊ�գ�(��,B):��ǰ��Ϊ�������ΪB��(��,B,��)����ǰ��Ϊ'��'�����ΪB����ǰ�ֵĺ�һ����Ϊ��������������Ȩ�ض�����ѵ��ʱ�õ��ġ����ڱ�ǣ�O��M��E��һ��Ҫ����W1O��W1M��W1E,�Ӷ��õ�����S1O��S1M��S1E��
2.���ڵڶ��У�����Ҫ������ÿ����ǵ�һԪȨ��W2BW2O,W2M,W2E����B������ñ�ǵ�������Ϊ��S2B=Max((v(BB)+S1B),(v(OB)+S1O),(v(MB)+S1M),(v(EB)+S1E))+W2B����v(BB)��ΪB��B��ת��������Ȩ�ء����Ҳ����ѵ���õ��ġ�ͬ�����ڵڶ��е�O,M,EҲҪ����S2O��S2M��S2E��
3.һֱ���㵽���һ�У���ֵ���ֵ����б�ǣ��õ�S7B��S7O��S7M��S7E.�Ƚ����ĸ�ֵ�е����ֵ����Ϊ����·���ķ�����Ȼ���Ը�ֵ�ı�ǵ�Ϊʼ�� ���ݵõ�����·����
4.2.3 ����HMMģ�͵ķִ��㷨�Ľ����ԣ�
���ľ��������ҵ���һ�ֻ��ڶ����������Ʒ�ģ�ͣ�CHMM���ķ���,ּ�ڽ�����ִʡ��з����硢δ��¼��ʶ�𡢴��Ա�ע�ȴʷ����������ںϵ�һ�����ͳһ������ģ���С�
CHMMʵ���������ɸ���εļ�HMM�����,����HMM֮�乲��һ���зִ�ͼ��Ϊ�������ݽṹ;ÿһ���������ɷ�ģ�Ͷ�����N-Best����,����������õ����ɸ�����͵���ͼ�й����߲�ε�ģ��ʹ�á�

ͼ4-2
����,��Ԥ�����Ľ�,��ȡN-���·���ַַ���,���ٵصõ��ܸ�����������N�����зֽ�������,�ڴַֽ������,���õͲ�����ģ��ʶ�����ͨ��Ƕ������������,�����β�ȡ�߲�����ģ��ʶ���Ƕ���������������ĸ��ӵ����ͻ�������Ȼ��ʶ�����δ��¼���Կ�ѧ��������ĸ��ʼ��뵽��������з�����ģ����,δ��¼�������������Ϊ����,����ͨ��һ�������ֺ�ѡ����ľ����������ȫ�����ŵķִʽ���Ͻ��д��Ե�������ע��
ԭ���з��Ǵʷ�������Ԥ��������,��Ҫ�����ǽ�ԭʼ�ַ����з�Ϊ�ִ�ԭ�����С��ִ�ԭ��ָ���Ƿִʵ���С������Ԫ,�ڷִʹ�����,������ϳɴ�,���ڲ���������һ����֡��ִ�ԭ�Ӱ�����������,����Լ��ɵ��ֽڡ��ַ������ֵ���ɵķǺ��ִ����硰2012.9���������չ��Ӧ�з�Ϊ:2012.9\��\��\��\��\��\��\չ��
�ڷִ��������������Dz�ȡ����N-���·�����з�������ԡ������˼�����ڳ�ʼ�α����зָ���P( W)����N�����,��Ϊ�ִʽ���ĺ�ѡ���ϡ���δ��¼��ʶ�𡢴��Ա�ע�ȴʷ�����֮��,��ͨ�����յ����ۺ���,������������Ž����ʵ����,N-���·�������������зַ�����ȫ�зֵķ������ۺϡ�
ͼ4-3
��δ��¼��ʶ�������ϣ����ǶԳ�ʼ�зֵõ��ĸ����ʰ�������δ��¼��ʶ���е����ý��з���,����������IJ�ͬ���ó�Ϊ��ɫ��

ͼ4-4
����һ�������ij�ʼ�зֽ��W=(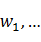 ,),��һ����ɫ���ϵķ����ڣ��ٶ�R=(
,),��һ����ɫ���ϵķ����ڣ��ٶ�R=(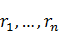 )ΪC��ij����ɫ���С�����ȡ�������Ľ�ɫ����R#��Ϊ���յĽ�ɫ��ע������͵�3�������ִʵ��Ƶ���������,�������տ��Եõ�
)ΪC��ij����ɫ���С�����ȡ�������Ľ�ɫ����R#��Ϊ���յĽ�ɫ��ע������͵�3�������ִʵ��Ƶ���������,�������տ��Եõ�
R#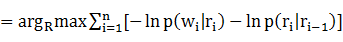
R#����ͨ��Viterbi�㷨[26]ѡ�ŵõ���
���ӵ����ͻ���������Ƕ������ͨ��Ƕ��������������δ��¼��,�硰������·�������ܶ����͵�ӱ������ݡ�����������Ƕ��δ��¼��,���ǵ������ǣ��ڵͲ��HMMʶ�������,��ʶ�����ͨ��Ƕ��δ��¼��,Ȼ���ڴ˻�����,ͨ����ͬ�ķ�����ȡ�߲�����ģ��,ͨ����ɫ��ע��������ŵĽ�ɫ����,�ڴ˻�����,��һ��ʶ���Ƕ��δ��¼�ʡ�
������������ִ��㷨�����㷨����CHMM�ĵ�2�㣬Ҳ���������е�δ��¼��ʶ����ɺ���С����ȣ����ǿ������еĴʷ��ࣺ
���У����Ĵʵ������е�ÿ���ʶ�Ӧ������Ǹôʱ����������ٶ����Ĵʵ�������Ĵ���Ϊ|Dict|�������Ƕ���Ĵ��������У�|Dict|+6������һ���ִ�ԭ������S��S��ij�����ִܷʽ����Ϊ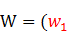 ,��,
,��,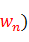 ��W��Ӧ��������м�Ϊ
��W��Ӧ��������м�Ϊ ��ͬʱ������ȡ�������ķִʽ��W#��Ϊ���յķִʽ������
��ͬʱ������ȡ�������ķִʽ��W#��Ϊ���յķִʽ������
W#
���ñ�Ҷ˹��ʽ����չ�����õ�
W#
�������״̬��������Ϊ�۲�ֵ������һ��HMMչ������
W#
�����У�Ϊ���ӵĿ�ʼ���BEG����ͬ��
Ϊ���㷽�㣬���ø����������㣬��
W#
������ �Ķ��壬���
�Ķ��壬���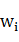 �ں��Ĵʵ���¼�����Եõ�=����ˣ�
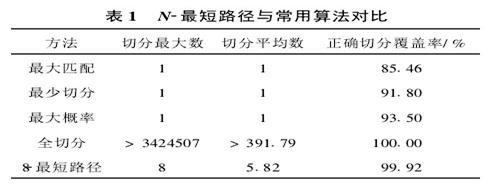
�ں��Ĵʵ���¼�����Եõ�=����ˣ�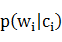 =1���ڷִʹ����У�����ֻ�迼��δ��¼�ʵ�����ͼ2�У����Ǹ����ˡ�ë��1893�굮�����Ķ�Ԫ�зִ�ͼ����������ķִʽ�����Ǵӳ�ʼ�ڵ�S�������ڵ�E�����·�������ǵ��͵����·�����⣬���Բ�ȡ̰���㷨����Dijkstra�㷨������⡣
=1���ڷִʹ����У�����ֻ�迼��δ��¼�ʵ�����ͼ2�У����Ǹ����ˡ�ë��1893�굮�����Ķ�Ԫ�зִ�ͼ����������ķִʽ�����Ǵӳ�ʼ�ڵ�S�������ڵ�E�����·�������ǵ��͵����·�����⣬���Բ�ȡ̰���㷨����Dijkstra�㷨������⡣
�塢������������������
5.1 �㷨ʵ��������Ľ�����
��5-1ͼ��ʾ�����������ĵ�ͨ�������������Ʒ�ִ�ģ���������ԭ���з֣�δ��¼��ʶ���Ա�ע�õ������ķִʽ�����ٸ��ݷִʽ��������˹���˵ķ�ʽ��Ӧ�÷ֵ�һ��Ĵʼ���ʵ䣬�Ա��Ż��ִ�Ч�����õ����εķִʽ���ٸ��ݴ��Թ���ģ��������ʡ����ʡ����ݴʹ��˳������õ��ؼ��ʣ��Ӷ��Ϻ��˳�������
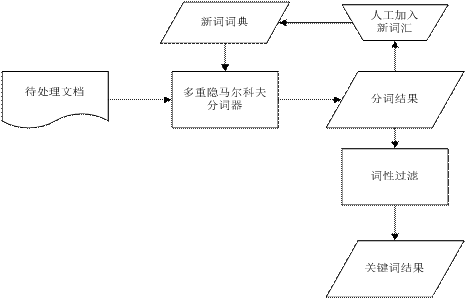
ͼ5-1
5.2 �ִ�Ч������������
���ǿ��Բ����˹���ע�ķ������������ı��ķִʣ����÷ִ��������з֣�Ȼ��ȶԶ��߲�𣬴Ӷ������ִ���Ч�������Խ������ϵͳ�����ۣ�������Ҫ�����¾�ȷ�����ٻ��������������������ۡ�

��Ӧ�ڷִ�ϵͳ����Ҫ�õ���ȷ�����ٻ��ʡ����Ӧ����Ϊ��
Tp �ִ���ȷ�������� Fp �ִʴ���������� Fn δ��ȷ�ִʵľ�������
ע��һ�仰���ж���ִʽ����
��������
���������������ķִ��㷨������ڴ��ģ���Ͽ��ͳ���㷨�������з������б��ֱȽϳ�ɫ��һ�����������Ĵʷ��ĸ����ԣ���ȫ������������ִܷʺ���ʵ�֣����������ִܷʻ��������˹���Ԥ�������������µĴʻ��������յ��ȽϺõ�Ч�������������ķ�������ϵͳ�У��ִ�ģ�����Ϊ�������������ش�ϣ�������ܹ�ͬ̽�������ָ��õķִʷ�����
����ʵ���ҵ���Ŀ���������г���Ӧ�õĻ����о���Ϊ������ij������λ�ṩ�˴�ֱ����������������ƶ��������ھ�ϵͳҲ�����Ǻ�����һ���������зִʻ������Ǵ���һ�������о����������ڴ���һ���ĺ�����



































