 分享到人人
分享到人人将图片型PDF文件转换生成文本型PDF文件还可以通过 “工具”→“文档处理”→“优化扫描的PDF”路径实现,并可进行应用自适应压缩、小文件/高质量、滤镜、OCR识别等各项设置(如图8所示)。经尝试,利用默认设置即可取得良好效果,与采用“文本识别”方法基本等效,而采用多种不同设置生成的文本型PDF显示效果差别也不明显。
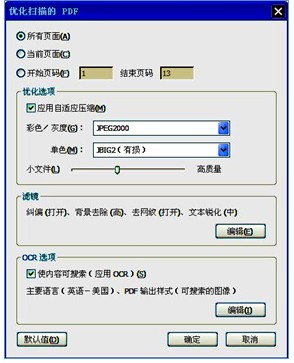
图8 “优化扫描的PDF”对话框
图9显示新生成的文献首页的完整页面,页面端正、整洁,可进行文字选中、复制等操作(如图10所示),也可用金山词霸取词(如图11所示)。
图9 新生成的文本型PDF文献页面
图10 选中和复制

图11 金山词霸屏幕取词
三、结 语
通过大型网络数据库下载已成为读者获得所需文献的主要途径。网络期刊文献大多采用PDF格式,以文本型为主,但仍有部分为图片型PDF文件。图片型PDF文件不支持以文字属性为运行基础的功能,例如复制、搜索、取词以及文献检索、学术不断检测,等等。采用Adobe Acrobat Professional 10.0将图片型PDF文件转换为文本型PDF文件,对于读者充分利用文献资源和数据库良好运行具有一定的实用意义。
笔者在阅读PDF格式英文文献时,习惯于采用金山词霸屏幕取词和翻查字典结合的方式,但是从网上获得的PDF文献,常为光栅模式无法取词;将PDF文件由图片型转换为文本型,可以有效解决这一问题。
(作者系:西安文理学院学报编辑部)
参考文献:
[1] 方宝花.期刊网络出版中的文件格式比较[J].情报技术,2005(2).
[2] 周雪莹.采用双层 PDF 形式将方正书版文件制作为可检索式 PDF 文件[J].编辑学报,2012(6).
[3] 陈庄.网络科技期刊插图图像质量调查与分析[J].科技与出版,2011(6).
[4] 李宗红.利用Adobe Acrobat Professional 8.0软件实现图片型PDF文件到文本型PDF文件的转换[J].中国科技期刊研究,2010 (l).
[5] 周雪莹.对“利用Adobe Acrobat Professional 8.0软件实现图片PDF文件到文本型PDF文件的转换”一文的质疑――与李宗红老师商榷[J].中国科技期刊研究,2011(6).
 |











 恭喜你,发表成功!
恭喜你,发表成功!

 !
!






















