 分享到人人
分享到人人摘 要:我国网络期刊文献大都采用PDF格式,且以文本型(矢量模式)为主,但也有部分为图片型(光栅模式)PDF文献。图片型PDF文献无法复制、搜索、取词,也不支持在线实时检索、学术不端检测等功能。利用Adobe Acrobat Professional 10.0可对扫描或其他方式生成的图片型PDF文献进行页面裁剪、OCR文本识别及页面校正,从而可以获得页面整洁、端正的文本型PDF文献。
关键词:Adobe Acrobat Professional 10.0;OCR文本识别;文本型;图片型
我国网络期刊出版采用的文件格式主要有CAJ、PDF和HTML三种[1],其中大多数为PDF格式[2]。PDF是世界上期刊网络版通用格式[3],我国的中国知网(CNKI)和国家科技图书文献中心(NSTL)也都提供PDF格式的期刊文献。生成PDF文档的常用方法包括通过其他软件中转和通过虚拟打印机。目前期刊编辑部广泛使用北大方正书版排版软件,可以直接或间接生成文本型PDF文献,其文字为矢量模式,可以进行选择复制、搜索查找、金山词霸取词等操作。但在缺少原始电子文件时,则需以扫描样刊的方式生成图片型PDF文献。图片型PDF文件整个页面为一个光栅图像,其中的文字不能被选中 [4-5],不仅无法复制、搜索、取词,也不支持在线实时检索、学术不端检测等功能,也常会出现边缘有多余文字以及页面不正等情况,从而影响到读者对文献的阅读利用和数据库系统的正常运行。本文利用Adobe Acrobat Professional 10.0,以自国家科技图书文献中心(NSTL)下载的英文文献“Relative measure index: a metric to measure the quality of journals”作为示例,对扫描(也可以是其他方式转换)生成的图片型(光栅模式)PDF文献进行裁剪,通过OCR文本识别转换为文本型(矢量模式),并同步对页面进行校正。
一、PDF文件页面裁剪
用Adobe Acrobat Professional 10.0打开所处理文献,首先对页面进行裁剪,裁剪需要逐页进行,而对于文本识别、启动注释等,可以整篇同时完成。
图1为所处理文献的首页,该文献为扫描生成的图片型PDF文件,无法进行文字选中、复制、搜索(查找)、翻译取词等操作,整篇文献页面横置,页面边缘有多余文字。
点击右上角“工具”按钮,打开“工具”窗格,选择“页面”→“裁剪”路径(如图2所示)。用出现的十字形光标选择裁剪区域(如图3所示),在选择区域内双击鼠标右键,出现“设置页面框”对话框(如图4所示),确定即可完成裁剪;这一步也可以单击鼠标右键,点击“设置页面框”命令,这时即直接将裁减框外的页面裁剪掉。

图1 所处理的扫描生成PDF文献(首页)

图2 工具―页面―裁剪 图3 选择裁减区域
工具窗格也可以通过菜单栏中的“视图”→“工具”路径打开,但不如通过工具窗格打开操作便捷、界面友好。
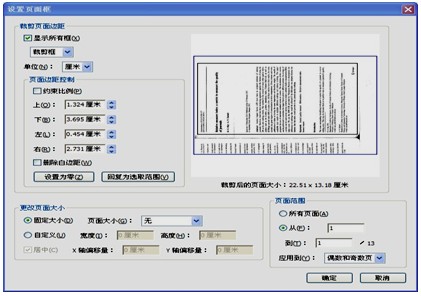
图4 “设置页面框”对话框二、将图片型PDF文件转换成文本型PDF文件
打开“工具”窗格,通过“识别文本”→“在本文件中”路径(如图5所示),打开“识别文本”对话框(如图6所示),点击“编辑”按钮,出现“识别文本-一般设置”对话框(如图7所示),设置OCR识别的主要语言,根据笔者观察选择中文或英文对识别效果没有影响,识别准确率都很高,但对生成的文本型PDF进行复制、粘贴操作中,如果设置语言与转换语言不一致,则可能出现乱码。分辨率选择300dpi,设置完成后确定,即可将图片型转换为文本型,并同步进行页面校正,将倾斜的页面转正,也可将横置页面转换为竖立;通过菜单“文件”→“另存为”→“PDF”,设置路径、重命名后加以保存。
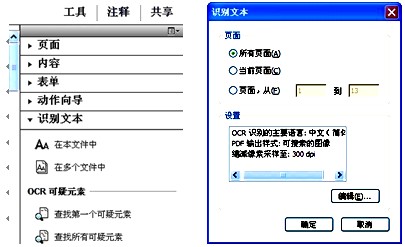
图5 工具窗格―识别文本 图6 “识别文本”对话框
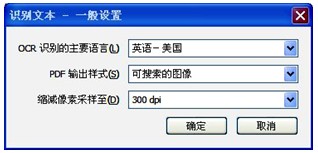
图7 “识别文本-一般设置”对话框
 |











 恭喜你,发表成功!
恭喜你,发表成功!

 !
!






















