 分享到人人
分享到人人【摘要】Web2.0时代以“用户为中心”、“集体智慧”和“分享精神”的特点使得以大众分类法(folksonomy)为主的社交网站得到了快速的发展和普及,但值得注意的是一部分以本体论模型(ontology)为信息构建基石但同时具备社交性质的网站正在厚积薄发。本文通过两种模型的理论根源对比和以“知乎”网为例的实际分析,认为在海量信息生产过后的互联网时代是朝着追求信息价值、管理和定位的方向发展的,以本体论模型构建起来的基于知识链结构的社交网络具有强大的生命力。
【关键词】 信息分类 大众分类法 本体论模型 知识链知乎
1 绪论
1.1研究问题和方法
本文试图以理论研究和实证分析,通过本体论模型(ontology)和现在较为流行的大众分类法(folksonomy)之间的对比来探讨基于知识链结构的社交网络的意义。
1.2研究内容
本文主要的内容包括:(一)Web2.0时代分类系统的现状;(二)大众分类法和本体论模型之间的根源对比;(三)以“知乎”网为例分析基于知识链结构的社交网络的特点。
1.3研究对象
本文选择网络问答社区“知乎”网为例进行分析,主要原因如下:
(1)我是知乎的heavy user。在我用知乎的很长一段时间内,都没有对它的信息分类系统进行过任何思考,但在本学期老师讲到Tag那一章时给了我启发,当我再去认真研究知乎的信息分类方法时,发现和如今广泛采用的大众分类法有所区别,它是建立在本体论模型基础上的。用一个比喻来形容这两者的区别就是前者更像是树叶,而后者是树干,用大众分类法时人们给问题标注tag就像将一片片树叶挂到树上一样,但是基于本体论模型基础上的分类方法(在知乎中以“topic”来表述)是将每一个问题投递到一类话题中,以树干的形式来培养。你通过某一树干能够追根溯源到许许多多的树干,而不像树叶之间相互零散的挂在树上。这种信息分类模式引起了我的极大兴趣;
(2)对话题层构建方式的好奇。前面提到了知乎的分类方式是建立在本体论模型上的,具体体现为话题层的结构,如图所示,知乎的分类方式是按照父级话题-子级话题来的,尽管这样能够更有效地构建起知识链,但是不同知识领域的话题层构建难度有很大差别,百度百科和wiki这种单纯以构建知识为主的网站的确适合这种结构,而我很好奇这样的结构能否适应中国网络社区的环境下带有社交性质的网络问答社区以及它是否具有发展的潜能;
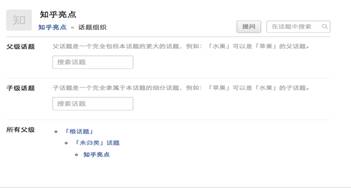 |
(资料来源:网站截图)
(3)中国需要一个更完善的高质量网络问答社区。在知乎出现之前,对于网络问答的需求大多依赖百度知道,但是百度的鱼龙混杂和质量下滑很快使我丧失了兴趣。而国外的Quora已经做的相当成功了,因此,尽管知乎沿袭了中国互联网发展的C2C精神(Copy To China),但至少弥补了国内的这块空白,并且它注重知识本身和精英文化的氛围也一度让我沉迷其中。
1.4此问题的研究综述
Web2.0的信息分类发展印证了Marieke Guy“互联网大幅度提高了信息交流效率并成为社群活动的重要组成部分”的观点。[1]目前为止,不少研究已经聚焦在大众分类法和本体论模型这两种信息分类方式上了。
1.4.1大众分类法的研究综述
20世纪90年代,博客开始流行;2004年Joshua Schachter开发的Del.icio.us风靡,基于标签的信息组织理念迅速应用到其他社会化软件中;2004年底,Thomas Vander Wal通过一个邮件讨论列表,首次提出“folksonomy”说法;2005年支持大众分类的网站开始大量出现,一些新的概念词汇如tag、folksonomy、social tagging、collaborative tagging成为代表大众分类法的术语。[2]
随着应用的发展,关于大众分类法的理论研究也迅速发展起来。Thomas Vander Wal认为它是用户基于个人信息管理的目的,使用习惯词汇对信息进行标注,以便再次查找使用的产物;[3]David Weinberger用“知识之树”来形容分类法的不同类型和发展阶段,并将tag和folksonomy比作从树上飘落的一堆“知识树叶”,认为标注活动运用了像大脑本身所使用的那种多重、重叠的关联,而不是死板的分类;[4]Adam Mathes指出了tag的非等级性特征,认为除了准确定位个人信息,相同的标签能够聚合整个信息空间中的所有相似内容,实现资源的共享;[5]Emanuele Quintarelli的研究表明用户在资源的共享过程中能够找到与自身拥有相同兴趣的人群,得到关于标签使用的反馈,从而影响其未来的行为,提出了大众分类法的形成和发展具有明显的社会化性质的观点。[6]
1.4.2本体论模型的研究综述
ontology一词来源于哲学,它是研究存在本质的哲学问题,由17世纪的德国经院学者郭克兰纽提出的。但是近几年,这个词被越来越多的用到计算机和互联网中,目前,对于本体论还没有统一的定义和固定的应用领域。Gruber将本体论定义为对概念化的精确描述(Gruber,1995),用于描述事物的本质。一个ontology往往就是一个正式的词汇表,其核心作用在于定义某一领域或领域内的专业词汇以及他们之间的关系,在这一概念的支持下,知识的搜索、积累和共享的效率将大大提高,web语言xml就是本体论的一项典型应用。
1991年Neches等人最早给出本体论在信息科学中的定义:给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延规则的定义;1993年Gruber定义本体论为“概念模型的明确的规范说明”;[7]1997年Borst进一步完善为“共享概念模型的形式化规范说明”;[8]Studer等人对上述两个定义进行了深入研究。
上述这段综述说实话我尚未能深度理解,但是就我个人的理解来说,由于机器并不能像人类一样理解自然语言中表达的语义,它是将文字看成字符处理的,因此本体论在计算机领域所发挥的功能就是讨论如何在人机互动之间形成一种语义层面的共识,也就是如何将概念形式化。
2 Web2.0时代分类系统的现状
纽约大学的克莱舍基有两本挺畅销的书,《未来是湿的》和《认知盈余》,分别讲了人们如何在缺乏组织的情况下生产信息和这些盈余信息的价值何在,深有启发。但进一步思考,其实如今,摆在我们面前的最大难题已经不再是信息生产,而是信息的组织、管理和定位。[9]
戴维・温伯格在《新数字秩序的革命》中提出了信息秩序的三个层次:在第一层中,我们安排事物本身。这种处理方式很快受到空间和数量的限制而被淘汰;在第二层中,信息被称为元数据。典型的代表有杜威的图书馆分类学,这种深受基督教和理性主义哲学影响的分类法随着人类知识规模的扩展已经显示出疲态;因此,戴维提出了第三层结构,比特时代。[10]在第一层和第二层中,信息的处理都是掌握在权威人士的手中,这显然不符合如今每个个体都是信息生产者的情形了。而当我们逐渐习惯于第三层秩序的时候,一些已经根深蒂固的思考方式会受到动摇和破坏,我们可以把这看作是互联网对人类知识生产能力的解放。
正是因为web2.0时代“以用户为中心”、“集体智慧”和“分享精神”等特征,[11]大众分类法得到了广泛的应用,比如最知名的Del.icio.us网站、书籍分类网站LibraryThing、影像共享网站youtube等等都是社交性非常强的网站。相比较而言,以本体论模型建构起来的网站比如wiki、百度百科都是强知识弱社交的。 但是,web2.0时代还出现了一些网站引起了我的注意,它即使重知识结构同时有具有社交网络的性质,Quora、知乎这类网络问答社区就是典型代表,虽然它们是以本体论模型来架构信息,但信息的产生、组织和管理又是交给网民自身。本文想要探讨的,正是这类基于知识链结构的社区网络的特征和意义,让我们先从这两种信息分类方式的根源谈起。
3 大众分类法和本体论模型之间的根源对比
大众分类法和本体论模型都属于人类处理信息分类的方法。分类是人类认识事物的一种思维方式,是人类思维活动的一种本能。[12]并且我们处理信息的方式随着时代的发展会产生不同。比如我国春秋战国时期,孙旭培在《华夏传播论》中描述我国古人将知识划分为经、史、子、集四类;1876年杜威提出的十进制图书馆分类法至今还被许多图书馆所沿用;而到了Web2.0时代,海量的信息体现出无序化、多样化和关联性的特征,并且随着人们的强介入,信息生产已经逐渐成为生活必需品的一种了。在这样的时代背景下,信息分类的方法走向以大众为基础的模式,大众分类法和本体论模型逐渐被信息学科重视起来。
在论述两者的不同之前,我想先提一下关于人类日常语言表述的两个学派,逻辑实证主义和日常语言学派。逻辑实证主义者认为,人类的日常语言充满谬误,容易引起哲学混乱,有必要重构一个像数学一样完美的逻辑语言体系;而日常语言学派则认为,人类的日常语言是非常合理而符合现实的,“完美”的逻辑语言并不存在而且也不符合现实;唯一的问题在于人们使用语言的时候出了一些方法上的问题。
我倾向于日常语言学派更符合未来信息的发展模式。前者用数理逻辑的构建体系来处理当下海量的信息只会陷入无限微观的悖论中,当然后者同样也存在着问题,就是你无法要求每个人对于日常语言的掌握都能做到维特根斯坦的高度,对于海量、无边无际并且无序的信息,大众分类法的典型代表tag的确是目前应用最广泛并且被广泛接受的组织方式,但是tag对于语义的精确度和更高的系统化要求是存在缺陷的。那么本体论模型能否弥补这一缺陷呢?
3.1 大众分类法的理论根源
大众分类法某种程度上来说是维特根斯坦“家族相似”观点的具体体现。维特根斯坦的观点是反“本质主义”的,本质主义者认为同一类事物之所以成为这类事物,是由于它们具有共相(共同的本质),人类用定义来规定事物的这种本质。但是维特根斯坦提出,事物根本就没有共同的本质,而是“家族相似”,就如同一个家族中的成员间有的眼睛相似、有的神态相似,人们在日常生活中使用名词只是为了交流的方便,本质或者共相是形而上学的东西,过分依赖只会混淆人们的认知视野。[13]
因此,在传统的分类方法中,名词之间是依靠他们所指的概念来联系的,而在大众分类法中,除了“相关度”之外,再也没有正式的关系了。
Gene Smith提出大众分类法的四个特征:独立进行、被聚合的、被推断出来的和任何推断方法都是有效的。[14]也就是说,以大众为基础的自下而上的分类方法是依靠使用的统计来联系的,而不是依靠语义关系。打个比方来说(如图1),在新浪微博上有两百个标记为“王力宏”、有两百个标记为“李云迪”还有两百个标记为“在一起”,对于这三个标记之间的语义联系能有什么呢?但是我们可以根据它们重合度的大小猜测它们在某方面的联系。而这在传统分类中王力宏很有可能就被划入了歌手一类,李云迪则被划入钢琴家一类。
大众分类法倡导了一种新的立场,我们不再追求唯一的、大一统的信息模式,而是以碎片式的结构代之,而这些碎片之间的联系,只有当人们需要的时候才得以显现。
3.2 本体论模型的理论根源
本体论的哲学渊源最早追溯到亚里士多德时代,它在哲学中的定义为“对世界上客观存在物的系统地描述,即存在论”,是客观存在的一个系统的解释或说明,关心的是客观现实的抽象本质。[15]上文提到了大众分类法从根本上和本质主义是相对立的,需要注意的是本体论不完全等同于本质主义,本质主义是假定事物具有超历史的、普遍的永恒本质,不会因时空的变化而变化。而本体论提供了在一个领域内部不同主体(人、机器、软件系统等)之间进行交流的一种语义基础,它通过捕获该领域的知识,提供对该领域知识的共同理解,给出该领域内词汇之间相互关系的明确定义。
本体论模型在知乎中体现为,不再以标签来定义问题,而是用户将问题“添加”到“话题”,就好像一个话题就是一根树干,用户每添加一个问题就给这根树干加了一点肥料,并且知乎允许所有用户来共同编辑话题,这样处理的好处将在第四节详细描述。
因此,大众分类法和本体论模型之间的差别,如表格所示:
|
|
|
|
|
哲学根源 |
维特根斯坦的“家族相似” |
本体论概念 |
|
信息之间的联系 |
相似性 |
以知识领域划分 |
|
信息组成方式 |
碎片化的结构 |
话题层级 |
|
信息分类方式 |
一个对象可以分入多种类别 |
一个对象可以涉及不同领域 |
(资料来源:自制)
4 以知乎为例分析基于知识链结构的社交网络的特点
其实根据前文的讨论,可以达到共识的是大众分类法适合于强社交的网站,而本体论模型适合于强知识的网站。现在的问题在于,对于网络问答社区来说,社交和知识都是非常重要的两块内容,拿知乎来说,它的很多问题寻求的不是权威和标准答案,而更注重个体经验的分享。但是,其高质量的精英定位又要求它不能走入社交依赖中,必须注重网站知识链的构建。下面通过分析知乎的具体设计来解释其如何在两者间寻求平衡
4.1 知乎的基本特点
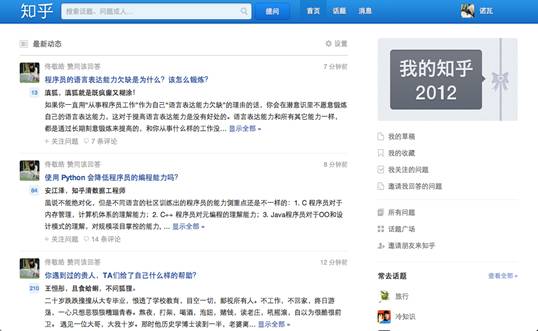
4.1.1首页
如图所示,是知乎的首页,可以分为四块:(1)左侧的最新动态,它是以典型社交网络的特点时间轴来显示的,用户登陆网站最先看到的是自己所关注的用户的最新动态,并且同时可以对问题添加关注和评论;(2)右栏上侧的管理信息,包括“我的草稿”、“我的收藏”、“我关注的问题”和“邀请我回答的问题”;(3)右栏中侧的邀请功能,用户可以通过邮件、微博等方式邀请好友加入知乎;(4)右侧下方的推荐板块,这是知乎运营方根据用户在网站的行为进行精确的推荐。
可以看出,知乎首页的布局是重社交性质的,无论是以时间轴为主线、邀请好友加入还是精确的定位推荐,都体现了web2.0时代“以用户为中心”的精神。
4.1.2问题页
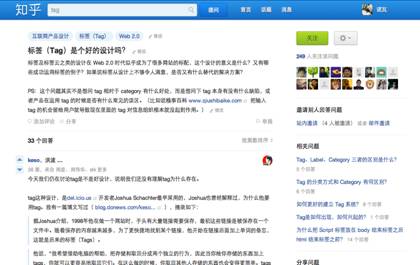
这是知乎最主要的问答页面。
首先,我们注意到问题的上部分显示着三个标签,在知乎中这被称为话题(topic),用户不是往问题上添加各式“话题”,而是将问题投递到“话题”,并且话题旁边是有修改键的,也就是每个用户都有权利更改不适合的投递。
其次,右栏有关注话题、关注的人、邀请、相关问题和分享问题的功能,可以看出,知乎在架构信息的同时还是非常注重社交网络的特性的。
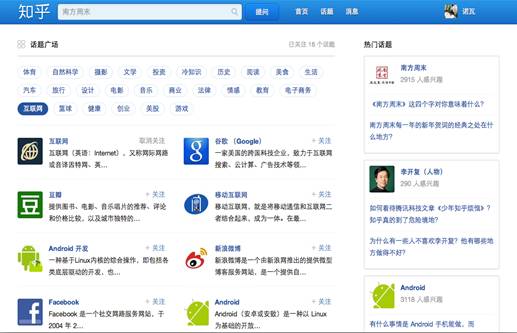
4.1.3话题广场
这个页面充分体现了知乎的知识架构。在父级话题部分的分类是比较大的,这是我关注的16个话题。当我们选中某个父级话题,比如互联网,就会出现许多子级话题,比如互联网、谷歌、豆瓣等等,当你点进某个子级话题时,就会呈现许许多多个问题,你可以进行搜索、选择精华、关注、提问回答等等。
4.2知乎的设计意义
从对知乎基本特点的分析可以看出,它基于本体论模型的知识建构使得它的知识链结构非常清晰。不像以人际链为主的社交网络,我们往往在某个标签下会看到杂乱无章、五花八门的各式内容,犹如信息垃圾的海洋,我们很少有人会乐意在这上面花费时间。但知乎不同,我常常在不经意间就在问题的链接再链接中花费大量的时间,并且还有获取知识的满足感。
但另一方面,知乎是以“人”为中心的。用户对于话题和问题的处理是非常自由的,并且关注问题不只是知乎唯一的维度,关注人是它另一个非常重要的维度,以我个人的实际经历来说,有一次我的某项作业需要一些关于日本动漫方面的知识,于是我在知乎寻找日本动漫的话题并且在某个专业详细的回答下通过私信联系到了回答者本人,一位业界人士,进一步询问到了很多单凭网络检索很难获得的信息。
可以说,知乎文化正是在这样的土壤中孕育出来的。它并不力求做一个海量、高质量的知识库,也不简单成为各种论坛的叠加,以垂直内容和人气来维持运营。正如知乎团队中的周源所言,知乎想要做的是满足一种随处可见的需求――一个人大脑中从未分享过的知识、经验、见解和判断力,总是另一群人非常想知道的东西。
4.3知乎的隐忧
当然,这样的设计也并不是十全十美的。以本体论模型构建知识是需要团队相当大的成本和精力来维护的,而且往往可能落得事倍功半的下场。
比如,不同知识领域的话题层建构难度有很大差别,像科技/经济学这些近代科学更简单一点,而信仰/观念等问题则相当困难。本体论的建构方法需要一个非常强大的团队进行维护;
又比如,如何避免大众自主的投递对知识构建的干扰。特别是在之前提到的困难领域,如何排除多元问题中个人见解差异对问题分类的影响也是个难题。在知乎上常出现的一种情况就是两人不断地为问题的投递争论,你修改完我修改,始终得不到一个定论。
但无论如何,知乎的观念和尝试是有趣的并且值得进一步探讨的。知乎团队对于信息的责任感是所有身处web2.0时代的中流砥柱们值得学习的。
5 结语
通过理论分析和对于知乎基于实际体验的分析,我认为,互联网的下一步很有可能还是会重新回到垂直化、部落化的形态。物以类聚人以群分是永恒的真理,当我们逐渐厌倦了别人每天分享个人心情、食物的网页页面时,单纯以社交为核心概念的网站会失去活力。在使用大众分类法组织人际链条的同时,注重基于本体论模型的知识链的构建,才能为web3.0的到来提供充足的养料。 特别是在中国的互联网环境中,像某些校友的所作所为,依赖人际链条实行营销盈利的模式,在我看来是不长久的。我始终相信人是会回归理性的,海量信息生产的web2.0过后,3.0一定是一个真正意义上注重信息价值、知识结构的信息时代。
因此,我看好基于知识链结构的社交网络的发展,尽管大众分类法的势头非常强劲,但单纯发展大众分类法依旧很难对海量信息的处理达到价值层面的要求,本体论模型的概念能在何种方面、多大程度与大众分类法相结合,我想可能是一条有意义的思考道路。
参考文献
1. Gruber TR.A Translation Approach to Portable Ontology Specification. Knowledge Acquisition,1993,5
2. Marieke Guy. Blogs, Wikis and more: Web 2.0 demystified for learning and teaching professionals.
http://www.slideshare.net/MariekeGuy/blogs-wikis―and-more-web-20-demystified―for―learning―and―teaching―professionals,2009,l l,18
3. Wal Thomas V. Folksonomy.
http://vanderwal.net/folksonomy.html.2010,3,22
4. David Weinberger. Taxonomies and Tags From Trees to Piles of Leaves. 2010,4,19
5. Mathes A. Folksonomies―Cooperative Classification and Communication Through Shared Metadata 2009,4,19?
6. Emanuele Quintarelli. Folksonomies: power to the people. 2010,4,21
7. Borst W N. Construction of Engineering Ontologies for Knowledge Sharing and Reuse. PhD thesis, University of Twente, Enschede,1997
8. 于明洁,《互联网社会标注及其概念结构研究》,2010年6月
9. 魏武挥,《信息生产之后》,《网络传播》2012年第6期
10. 戴维・温伯格,《新数字秩序的革命》,中信出版社,2008年11月
11. 邓建国,《强大的弱链接》,复旦大学出版社,2011年12月
12. 维特根斯坦,《哲学研究》,上海人民出版社,2005年5月
13. Gene Smith,《标签:标记系统设计实践》,机械工业出版社,2012年6月
14. 邓志泓,陈捷,杨冬青等,《ontology研究综述》,北京大学学报,第38卷,第5期,2002年9月
15. 弗兰克・韦伯斯特,《信息社会理论》(第三版),北京大学出版社,2011年6月
[1].Marieke Guy. Blogs, Wikis and more: Web 2.0 demystified for learning and teaching professionals. http://www.slideshare.net/MariekeGuy/blogs-wikis―and-more-web-20-demystified―for―learning―and―teaching―professionals,2009,l l,18
[2] 于明洁,《互联网社会标注及其概念结构研究》,2010年6月
[3] Wal Thomas V. Folksonomy. http://vanderwal.net/folksonomy.html.2010,3,22
[4] David Weinberger. Taxonomies and Tags From Trees to Piles of Leaves. 2010,4,19
[5] Mathes A. Folksonomies―Cooperative Classification and Communication Through Shared Metadata 2009,4,19?
[6] Emanuele Quintarelli. Folksonomies: power to the people. 2010,4,21
[7] Gruber TR.A Translation Approach to Portable Ontology Specification. Knowledge Acquisition,1993,5
[8] Borst W N. Construction of Engineering Ontologies for Knowledge Sharing and Reuse. PhD thesis, University of Twente, Enschede,1997
[9] 魏武挥,《信息生产之后》,《网络传播》2012年第6期,p92
[10] 戴维・温伯格,《新数字秩序的革命》,中信出版社,2008年11月,p12
[11] 邓建国,p172
[12] 邓建国,《强大的弱链接》,复旦大学出版社,2011年12月,p160
[13] 维特根斯坦,《哲学研究》,上海人民出版社,2005年5月
[14] Gene Smith,《标签:标记系统设计实践》,机械工业出版社,2012年6月,p84
[15] 邓志泓,陈捷,杨冬青等,《ontology研究综述》,北京大学学报,第38卷,第5期,2002年9月











 恭喜你,发表成功!
恭喜你,发表成功!

 !
!






















