 ����������
����������һ���о���Ŀ��ʵ����
����ʱ���ķ�չ�������ϵ���Ϣ���ֱ�ըʽ���������Ż���վ������ý���Ѿ������ǻ��������ݵ���Ҫ��Դ�������罻ƽ̨��������̳��ÿ�춼�������������Ϣ���ڴ�������Ϣ�м�ʱ����Ч����ȡ���м�ֵ����Ϣ���Ϊ�˸���������վ����Ե���Ҫ���⡣��������Ϊ���ʻ������������ۺ�������ý��֮һ��һֱ�����ڼ�ʱ�����м�ֵ����Ϣ������ϢʱЧ�Ե�Ҫ��ҲԽ��Խ�ߣ���ijһ�����潫���ֵ����Ϣ��ʱ��չ�ָ��û�Ҳ��Ϊ����վ�ı�ȻҪ����ο��ٵ�ɸѡ�����ı�Ҳ��Ϊ����վؽ����������⡣
�����ı���ɸѡ���Ȿ���Ͽ��Թ��Ϊ�ı��Ķ���������⣬��ͬ��ͳ���ı�������ȶ������������ԵIJ����ԡ�һ���ı������IJ���ȷ�ԣ�������ı�������Ϊȷ������ν���ż�ֵ����������������Ϣ��ҵ�ķ�չ��������Internet�ı�ըʽ��������Ҫ�������������ݳ��ֺ������ص㣬��ͳ���ı������㷨��KNN��SVM����Ҷ˹�ȣ��ڼ����������Ѿ����ԴﵽҪ��
���о�����ѡȡ��Ϣ���������Rocchio�㷨������������˻���MapReduce���ģ�͵IJ�����ơ�ʹ���������ڴ����ݵ�ʱ�������¼�ʱ�Ľ����Ž��з��࣬����������м�ֵ����Ϣ��������վ������ʱЧ�Ե�Ҫ��
�� ����ؼ�������
2.1���ڸĽ�TF-IDF�㷨������ѡ��
TF-IDF�㷨����Ϣ���������ڳ��õ�������ʾ�����������˼��Ϊ����ij������ijһ�ĵ��г��ֵĴ�ƵTF(Term Frequency)�ϸߣ��������˴������ĵ����٣����������ĵ�Ƶ��DF(Document Frequency)�ϵͣ�����Ϊ�˴������кܺõ��������������Ӧ����ϸ�Ȩ�ء�����
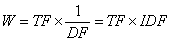 �� (1)
�� (1)
����IDF(Inverse Document Frequency)��ʾ���ĵ�Ƶ�ʡ�TF��IDF�Ļ����������£�
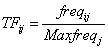 �� (2)
�� (2)
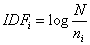 �� (3)
�� (3)
ʽ�У�freqij��ʾ��i�����ڵ�jƪ�ĵ��г��ֵĴ�����Maxfreqj��ʾ��jƪ�ĵ���Ƶ����ߵĴʳ��ֵĴ�����NΪ���ĵ�����niΪ������i���ʵ��ĵ�����
�����ִ�ͳ��TF-IDF�㷨��Ӧ�����ı�����ʱ���ڲ��㡣ʵ���ϣ���ij������һ������ĵ���Ƶ�����֣���˵���ô����ܹ��ܺô��������ĵ�������Ӧ����ϸߵ�Ȩ�ء�������[1]���һ������ı�����ĸĽ�TF-IDF�㷨���Ľ���IDF��ʽ��������ijһ���ı�C��IDFΪ��
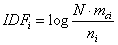 �� (4)
�� (4)
���У�mciΪij��C�а�����i���ʵ��ĵ����������C���⣬������i���������ĵ���Ϊki����ʽ��Ϊ��
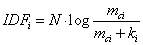 �� (5)
�� (5)
�ӹ�ʽ�п��Կ���IDFi��ֵ��mci����أ���ki����ء���ˣ����Ϲ�ʽ�������ֳ����ָĽ�˼�롣
2.2���ƶ��㷨
�ı�Doci�ھ����ִʡ�ȥͣ�ʺ�ͨ������������TF-IDF�������Ȩ��wij����ȡ����[2]������Ա�ʾΪ�����ռ�ģ��(Vector Space model, VSM)����ʽ���γ��ı����������磺

�˴�n��m�ֱ��ʾ�ĵ�����ʿռ��ά�ȡ��������������ƶȣ���Doci��Docj�������ƶ�simijΪ��
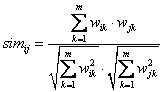 �� (6)
�� (6)
2.3 Rocchio�㷨
Rocchio�㷨��һ�ֻ����������������������˼������ͨ������ʵ����ÿ�����Ĺ����õ��ķ���ʵ����Generalized Instances��������ν��������������Ϊģ�������з���[3] ����������㷨�����KNN�����������㷨���Ը�Ч������ʵ�֡���Ȼ�ڷ��ྫ����һ�㲻�������㷨�����dz��ʺ�ֻ������ķ������⣬������A��~A�����⣬����ر���������Ϣ�Ĺ���[4]��
����������������ѵ�������ʼ״̬ʱ�����Ci����������ci��ÿһά�ȵ�Ȩֵ����0�����������ci�ĵ�jά��ȨֵcijΪ��
 �� (7)
�� (7)
����wijΪ�ı�����di��jά������Ȩֵ��CΪ�ı����壬kΪ�������������������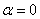 ��
��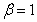 ��
��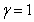 ��
��
2.4 MapReduce���ģ��
MapReduceģ��[5-9]��Google��˾���������һ�ֲַ�ʽ���ģ�ͣ�ר���ڴ��ģ���ݼ��ķֲ�ʽ���㡣�˺�Apache��������Ƴ���ԴMapReduce��̿��Hadoop����
MapReduce�Ĵ�����������ͼ��ʾ��

ͼ 1 MapReduce�Ĺ�������ͼ
Fig.1 The workflow diagram of MapReduce
MapReduce���ֲ�ʽ��������Map��Reduce������Ҫ���衣��MapReduce�У���������<key, value>����ʽ���ڵġ�Map���踺�������<key, value>���д���������ͬ����Ϊ<key, value>���м������м�������keyֵ�IJ�ͬ����Combine��Sort��Shuffle���̽����ݰ���ͬ��key�ϲ�Ϊ<key, list[value]>�ַ�����ͬ�Ľڵ����Reduce������Reduce���������зַ��������м�������Key���кϲ��Լ�����������������յĴ��������
���������������У������߲���Ҫ�����κ��йصײ�ֲ�ʽ���������飬ֻ��Ҫ��ע�Լ���Map��Reduce���������ɡ��⼫����˲��м����ʵ�ֹ��̣���ʹ�����߽�����ľ����ŵ����Ȿ����
��������MapReduce��Rocchio�㷨
3.1����MapReduce���ĵ���Ƶͳ���㷨
�������ݵĸ�ʽ���1��ʾ��

�����ĵ��������������ı�����������ࡢ�������Ǵ����࣬�ֱ���R��NR��Non��Ӧ��ʾ��
Map���̣��Ƚ��ĵ�D����Ϊ�ĵ����ID���ĵ�����C���ĵ�����A�����֣��ٰ����ݷִ�ȥ�룬���ѵõ��Ĵ�����Ϊvalue������Ѵ���������<�ĵ���,����>����Ϊkey�����α�������£�
Input: D
Output: <key, value>
(1) (ID, C, A) = parse(D)
(2) T = segment(C)
(3) for term in T do
(4) key = make_pair(ID, A)
(5) value = term
(6) output(key, value)
Reduce���̣�Map�Ľ�����뵽Reduce����֮ǰ����ͬkey��value�ᱻ�ϲ���һ���γ�<key, value_list>��Ȼ���ÿһ��keyͳ����value_list�в�ͬvalue����ʱ��value��Ϊ����term����Ƶ�������keyԭ����ΪReduce��key��������Ӧvalue_list�в�ͬ��value����Ƶ����ΪReduce��value�����α�������£�
Input: <key, value_list >
Output: <key, value>
(1) for term in value_list do
(2) freq = count(term, value_list)
(3) list.add( make_pair(term, freq))
(4) value = list
(5) output(key, value)
���õ�����������ʽ��
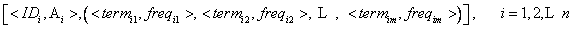
3.2ѵ����
��ѵ�����ݼ�Ӧ��2.1��������MapReduce���ĵ���Ƶͳ���㷨���ó����ÿһ�ĵ��Ĵ�Ƶͳ�ƽ����Ȼ�����1.1�����Ļ��ڸĽ�TF-IDF�㷨������ѡ���������ÿ���ĵ���ÿ���ʵ�Ȩ��wij��Ȼ��ȡȨ������ǰK������Ϊ���ĵ��������ʺϲ������ĵ��������ʣ���������ʿռ䣬��ΪVSM��ά�ȿռ䣬��ΪV��
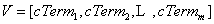
Ȼ��֮ǰ�õ����ı�Ȩ�ؽ��ӳ�䵽�����ʿռ��ϣ��Ϳɵõ��ı���������������Ϊ��
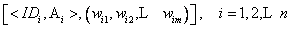
���У�Ai��ֵΪR��NR�������ϵĽ�����빫ʽ(7)�У�����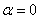 ��
�� ��
��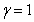 ���ɵó�����������������cR�ͷ�����������������cNR������
���ɵó�����������������cR�ͷ�����������������cNR������

�ɹ�ʽ(7)��֪��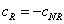
3.3�����
�Դ��������ݼ�Ӧ��2.1��������MapReduce���ĵ���Ƶͳ���㷨���ó����ÿһ�ĵ��Ĵ�Ƶͳ�ƽ����Ȼ�����ÿһ�ĵ��������ʿռ�V�ϵ�Ȩֵ���õ���

����Non���������ı����Ǵ����ࡣ���������Ҫ������Map�Σ���Ŀ���ĵ��������������ľ���Ϊ���ݣ������ڷ��������ͨ����ʽ(8)���ϸ����������������Դﵽ������Ч����
 (8)
(8)
����ciΪ��i���������������wi�Ǹշ�Ϊ��i����ĵ�������a��bΪ����ϵ������a + b = 1��
Map���̣��������������Ĵ������ı�����VD����Ϊ�ĵ���ID���ĵ�����������wD = (w1,w2, �� ,wm)��Ȼ������������������������cR��cNR�����뷴�����ƽ��з��࣬����ĵ�����Ϊvalue������ĵ����������Ϊkey�����α�������£�
Input: VD, cR, cNR
Output: <key, value>
(1) (ID, wD ) = parse(VD)
(2) value = ID
(3) sR = cos_similarity(wD , cR)
(4) sNR = cos_similarity (wD , cNR)
(5) if sR > sNR then
(6) key = ��R��
(7) cR = a *cR + b * wD
(8) else
(9) key = ��NR��
(10) cNR = a * cNR + b* wD
(11) output(key, value)
�����㷨��ԭ���ĵ�һ������Ϊ�ֲ�ʽ�Ķ෴������ͼ2�����������Чƽ̯�����ȷ�ȡ�
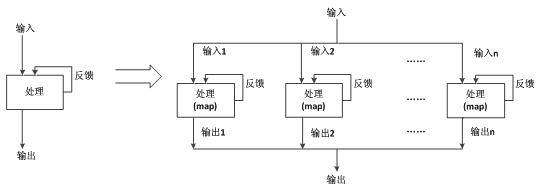
ͼ 2 ��һ�������෴��
Fig.2 Single feedback to multiple feedback
Reduce���̣�ͬ������Map���̺�Reduce����֮�䣬��ͬkey��<key, value>�Ժϲ�����Ϊ<key, value_list>�������ԼӴ���ԭ��������ɡ�α�������£�
Input: <key, value_list>
Output: <key, value>
(1) for doc in value_list do
(2) list.add(doc)
(3) values = list
(4) output(key, value)
���������㷨�������Ϳɵõ����ķ��������£�

�ġ�ʵ�鼰����
4.1ʵ�鷽��
ʵ�齫�Ӷ������ı�������ȷ�ʺ��ٶ��������������֣�ͨ��������MapReduce��Rocchio��ط����㷨�봫ͳ��Rocchio�㷨��KNN�㷨��SVM�㷨���Աȣ�����֤����������㷨�����ܡ�
ʵ�黷�����÷ֲ�ʽ����ƽ̨Hadoop(�汾0.20.2)������6���ڵ㣬ÿ���ڵ�����ã�CUPΪ4��3.2GHz��4GB�ڴ棬500GBӲ�̣�ǧ������������ϵͳΪUbuntu 11.04��
ʵ�����ݼ�Ϊ�����ռ����ĺ�����Ϣ�ı������ݼ��������ı�61800�����������������1400�������ŷ����������60400����ÿ���ı������ݸ�ʽ���2��ʾ����ȡ����Ϣ��ת��Ϊ��1��ʾ�ĸ�ʽ�����б�2�ı��Ϊ��1���ĵ���ţ���2�ı��⡢��������ҳ������Ϊ��1���ĵ����ݣ���1���ĵ��������ĵ���������Ӧ��ע��

ʵ��ָ������ٻ���(Recall)������(Precision)��F1ֵ�ͼ��ٱ�(Speed-up Ratio)����N��ʾ�ܵ������ı����ϣ�C0��ʾʵ�ʵ���������༯�ϣ�C1Ϊʵ�����ŷ�����༯�ϣ�D0��ʾ���б����������༯�ϣ�D1��ʾ���б�����ŷ�����༯�ϣ�T0Ϊ�Ľ�ǰ�ķ���ʱ�䣬T1Ϊ�Ľ���ķ���ʱ�䡣���У�
 �� (9)
�� (9)
 �� (10)
�� (10)
 �� (11)
�� (11)
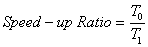 �� (12)
�� (12)
4.2ʵ�����������봫ͳ�㷨�Ա�
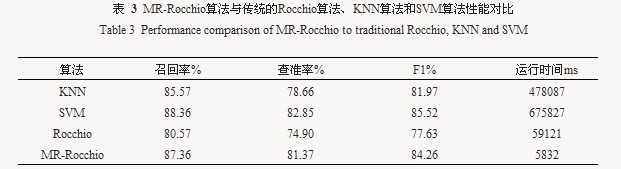
������MapReduce��Rocchio��ط����㷨�����¼��ΪMR-Rocchio�㷨���봫ͳ��Rocchio�㷨��KNN�㷨��SVM�㷨�����ܽ��жԱȣ��ɵõ�������3��ʾ ��
Ȼ����ļ�Ⱥ��ģ����Hadoop��Ⱥ�ֱ����1����2����3����4����5����6��������ͬ�Ľڵ㣬����MR-Rocchio�㷨���������ͬ���������õ�ʱ�䣬�õ��Ľ�����4��ʾ��

�������������Եõ��ڲ�ͬ��ģ��Ⱥ��������MR-Rocchio�㷨����㷨�ļ��ٱ���ͼ3��ʾ������SR��ʾ���ٱȣ�NΪ��Ⱥ�ڵ�������
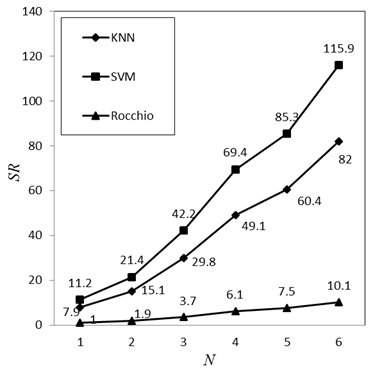
ͼ 3 MR-Rocchio�㷨��KNN��SVM��Rocchio�ļ��ٱȱ仯ͼ
Fig.3 Trend lines of speed-up ratio of MR-Rocchio with KNN, SVM, Rocchio
������ʵ�������Կ������ڷ���ɸѡ��ȷ�ʷ������MapReduce��Rocchio��ط����㷨����ڴ�ͳ��Rocchio�㷨�нϴ���������������KNN�㷨��ֻ������ѷ��SVM�㷨�������ڷ���ɸѡ�Ĵ����ٶȷ��棬����MapReduce��Rocchio��ط����㷨���������MapReduce�����ڴ����ݴ�����������ƣ�ִ�е��ٶȺ�Ч��ԶԶ���������㷨����������һ����Χ�����ż�Ⱥ��ģ�����Ӷ��������ӡ�
�塢����
�����ı��ķ���ɸѡ�����Ű������������������Ҫ�ĵ�λ�����ã���������Ϣ�ı�ըʽ��������ͳ���ı������㷨�ڱ�֤Ч����ǰ���£������ٶ����ԴﵽҪ������Rocchoi�㷨Ϊ�����������˸Ľ���ͻ���ڴ��ģ�������ݼ�������ʱ���������ƣ����������ض��������еĺ��������ı��ķ���ɸѡ���⡣������MapReduce�����������䴦���������ݵ����ƣ���ߵ��㷨�Ĵ����ٶȡ��о�����������MapReduce��Rocchio��ط����㷨���ڱ�֤ȷ�ȵ�����´�����ϵͳ��ִ���ٶȺ�Ч�ʡ����������Ŷ�ʱЧ�Ե�Ҫ���ܼ�ʱ�ĴӴ��ģ������������ɸѡ���м�ֵ�����š�
Ŀǰ���������Ż������������Ļ������Ż���վ�Ѿ��ڻ���MapReduce�ļ��������������紫ý��ҵ��ǰ�У����Դ�ȡ���˳���ɹ۵�����ЧӦ����������Facebook���Լ����ڵ��������ƽ̨��Ҳ�Ѿ����˹㷺��Ӧ�ã�δ��ע���Ǵ����ݽ��й㷺�ռ�Ӧ�õ�ʱ�������������Ŵ�ý��ҵҲ�϶�������ʱ�������ƣ���������Ϊ����������Ϊ���Ĵ���������Ϣ����ƽ̨��Ҳ�ǹ��ʻ������������ۺ�������ý��֮һ���������δ�����������ʱ���м���ռ������λ�ã�����MapReduce��Rocchio��ط����㷨������һ�����������һ���MapReduce�����������ص������ھ���Ҳ��ٽ�������ҵ������Ե���չ����ʹ�����������������١�
�ڴ����ݵ�ʱ�������£��������ı��ھ��㷨���зֲ�ʽ���о����м�ǿ����ʵ���塣������Ȼ����Ҫ�Ľ�֮����δ���Ĺ����ص�������ط���ϵ��a��bȡֵ���Ż��Լ��ı�����ѡ����Ż��ϡ�
�����
[1] ����,��ʱ��,����. �����ı�����TFIDF�����ĸĽ���Ӧ��. ���������, 2006, 32(19)��76-78��
[2] �ź���,����֥. �Զ��ı���������ѡ���о�. ��������������, 2006, 27(20)��3838�C3841
[3] ���ι�. �����ı����෴��ѧϰ�о�[D]. ����: �������ӿƼ���ѧ, 2009
[4] �����,�����,������. ������Ϣ����ϵͳ�������ʵ��. �����������Ӧ��, 2005(21)��156��158��
[5] R L?mmel. Google��s mapreduce programming model��revisited. Science of Computer Programming 70 (1) (2008) 1�C30.
[6] Y. Liu, Z. Hu, K. Matsuzaki. Towards systematic parallel programming over mapreduce. Euro-Par 2011 Parallel Processing, Part II, Vol.6853 of LNCS, Springer, 2011: 39-50.
[7] J. Dean, S. Ghemawat. Mapreduce: simplified data processing on large clusters. Communications of the ACM, 2008, 51: 107�C113.
[8] C. Buckley,G. Salton, J. Allan. The effect of adding relevance informationin a relevance feedback environment, InternationalACM SIGIR Conference,1994: 292-300.
[9] T. White. Hadoop: The Definitive Guide. O��Reilly Media,2009.











 ��ϲ�㣬�����ɹ�!
��ϲ�㣬�����ɹ�!

 !
!






















