 分享到人人
分享到人人摘要:随着大数据时代的到来,面对爆炸式的信息增长,最短时间内获取需要的信息是人们当前的迫切需求,随之将新闻恰当精确推送给用户,同时也就成为了各大新闻门户关注的焦点。信息膨胀问题导致信息获取效率也随之下降,让用户获取紧凑的个性化信息是每个新闻门户都面临着的最具挑战性的任务。本文通过分析传统的新闻推送模式,结合大数据时代的理念,提出了一种以人为核心的全新的新闻主动推送模式,它将能满足人们迫切的信息需求。
关键词:新闻推送关键词个性化
1引言
在这个信息量暴增的时代,人们面临着一个迫切而严重的问题,那就是信息过剩。通过统计人民网一天的新闻量,在分析三级网页链接后,发现了5000+的新闻。这仅仅是人民网一个网站的新闻量,加上目前各大主流的新闻门户,比如腾讯,百度,新浪,搜狐,网易,中国新闻网,环球时报,凤凰资讯等等。所有这些新闻网站一天的新闻量之和将会达到10万有余。面对如此多的新闻消息,人们无力从中找出可能感兴趣的消息,大多数人不会主动去关注新闻,而是利用碎片时间被动的接收一些头条新闻。
知乎上曾有人提问过:“在信息爆炸的社会里,你一般是利用什么时间去看新闻?每天会花多少时间去浏览新闻?你用什么方式获取高质量的新闻?”(链接附在参考资料里)。通过分析该问答的内容,可以总结出以下几点问题:首先,每天面对着这么多的新闻消息,多数人都不会主动关注,而是选择被动接收;其次,主动关注新闻的人,每天花在新闻上的时间大致在30分钟左右;接着,在从大量新闻中发掘感兴趣的信息时,有95%以上的信息是无意义的;最后,为了能高效的获取紧凑的兴趣信息,当前的方式主要是采用google reader这一类的阅读聚合器,通过订阅自己感兴趣的新闻,然后依靠阅读聚合器扫描更新,发布给用户阅读。
下图是当前主流新闻门户的手机客户端功能对比:
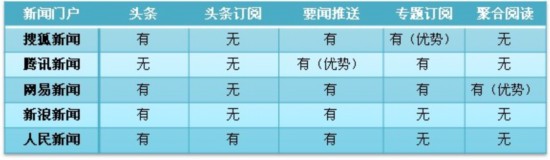
图1主流新闻门户的手机客户端功能对比
从表1中可以看出,各大门户网站为了帮助用户提高信息获取效率,目前采用的主要方式是专题订阅和头条。所有这些门户网站中,下载量(数据来源于360手机助手和豌豆荚应用下载量统计)最多的是搜狐新闻,它的优势在于它对于专题订阅的分类非常的详细,贴近人们的生活习惯;其次是腾讯新闻,它的优势在于及时性,对于最新要闻腾讯新闻总是最先报道;然后是网易新闻,它具有一个较新的功能――聚合阅读,但是这种聚合阅读并不是像google reader那一类的聚合阅读,而是网易新闻将相关的新闻聚合在一起让用户阅读;接着是新浪新闻,虽然没有专题订阅,但是它有专栏阅读;最后是人民新闻,它虽然有个自己独有的东西――头条订阅,但是头条的分类与新闻文本的分类相同,这其实是对于新闻文本分类的一个简单提取。通过对比不难发现,用户想要的就是贴近他自己需要的,随着大数据时代的到来,新闻推送将不再以新闻为核心,而会以人为核心,以人的行为信息作为基本出发点。
人是新闻信息的最终接收体,中间的各种传播媒介都不过是临时承载体,只有将人的各方面属性因素加入考虑,才能准确完成新闻信息的传播。随着新闻信息量的增长,新闻门户为了提升自己的影响力,除了有权威的新闻报道外,还需要有足够多的使用用户,而欲取得足够多的使用者,就必须做到让使用者能在最短时间内获取到他们需要的信息。换言之,站在新闻门户的角度来看,就是要保证信息的传播方向是正确的,不会成为用户的垃圾信息,这就需要从各个角度剖析用户的行为属性,并结合新闻本体内容,完成对用户和新闻的分类。
以人为核心的新闻传播方式,必然是新闻传播的未来趋势。人民网以信息权威性而具有足够多的用户,同时又拥有足够多的权威性的新闻信息,如果能把握这个重大机遇,基于这些新闻信息和用户的使用信息,较其他新闻门户先完善新闻传播方式从以新闻为中心到以人为核心的转变,人民网将成为新闻传播的核心,引导新闻传播发展方向。下面从技术角度,提出这种以人为核心的新闻传播方式的初步构想方案。
2任务概述
整个模式的任务是通过关键词来标识新闻信息,并结合人的行为属性来完成对新闻和人的分类。同时对于新出的新闻信息,通过归类分析,将其准确恰当的推送给需要的用户。而对于新的使用用户,由于没有其使用信息,没法对其进行分类,就需要将最近的热点事件推送给他供其选择,并记录其信息使用情况,以便于之后对其进行归类分析。
下面是整个模式的信息处理流程图:
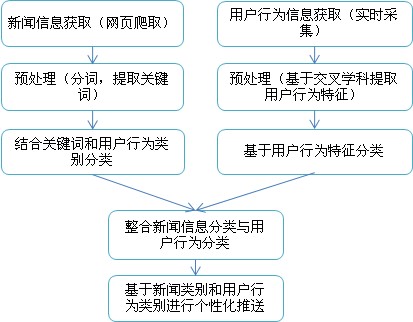
图2模式的信息处理流程图
3模式流程
模式流程包括两部分,分别是模式初始化和模式运作。
该流程只是对于新的新闻推送方式的一个简单的初步构想,具体的技术细节,在实际实施时可能需要做出调整。为了能清楚的表达出整个模式,其间选用的技术以简单明了且有效为原则,分词工具采用的事中科院的ICTCLAS,该分词工具与其他的开源分词工具如IKAnalyzer相比,不仅性能更优,而且具有词性标注功能,有利于下一步的关键词提取工作;关键词提取算法采用的是SKE(基于语义的中文文本关键词提取)算法,该算法相对于简单通用的TF.IDF算法的优势在于,它不需要采集大量的文档,而是通过分析文档的结构以及内容词的词性来完成关键词提取;推送新闻的格式采用RSS格式,这种格式既能保持新闻内容原本的html格式,同时语法简洁便于解析额外信息。
3.1模式初始化
- 为了得到热点词,需要采集近一周的新闻文档。根据当前新闻门户的信息阅读模式,主要的新闻信息出现于page_rank较低的网页,同时根据新闻的实时性,通过抓取网站中page_rank小于4的网页,同时发布时间小于一周的新闻来分析热点词。
- 使用ICTCLAS完成对上述文档的分词,然后采用SKE算法筛选出新闻关键词作为热点词,用于向新用户推送。
3.2模式运作
- 网站监测模块不间断的扫描目标网站,当发现新发布的新闻后,将其保存下来,并送入分词模块分词,并通过SKE算法获得该新闻的关键词,然后根据关键词并结合用户行为类别将其归类。
- 个性化推送模块根据文档的关键词以及文档的类别,以及用户的类别,将新闻消息准确的推送给需要他的用户。
- 同时用户推送模块,需要采集用户的行为属性,包括阅读时间,阅读地点,阅读内容所用时间,订阅的关键词等信息,用以对用户进行归类。
4初步方案
4.1网站监测
获取近一周的新闻文档集和实时监测网站内容更新并不是分开的模块,二者是统一的,只是需要设置不同的初始条件。
为了能更快的获取新闻文档集以及及时发现内容更新,程序分布在多台机器上运行,采用集中式并行方式,加速文档下载和更新监测。整个模块的机器的角色分为:Core和Task。Task按照网站的链接层次又分为Task_rank1,Task_rank2,Task_rank3等等。每一个Task_rankn可以包含一台或者多台机器。Task_rankn的机器负责网站第n层链接内容的获取。Task_rank1的任务是分析网站的第一层链接,即网站的首页,由于首页没有新闻文档,只有链接,这项任务很少,所以可以让Core承担这部分任务。也就是说具有Core角色的机器同时也是Task_rank1角色的机器。集群机器角色及其基本数据结构,常量和任务如下图:
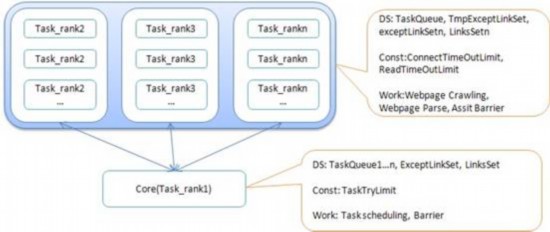
图3集群机器角色及其基本数据结构,常量和任务
整个模块的大致运行流程如下:
- Task_rank1获取首页中的链接,保存到第二级任务链接的队列中TaskQueue2中。
- Core根据TaskQueue2链接的数量,将其均匀分配到Task_rank2中,并等待Task_rank2将第三级链接返回来,并保存到TaskQueue3中。Task_rank2获取任务后,一个机器可以开多个线程,或者多个虚拟机去并行完成这些任务。对于一个链接,通过获取其内容,分析判断是新闻文档还是标题页。如果是新闻文档,则分离出其中的新闻信息,将其转化为RSS的Item格式,并保存到存储设备上,用于之后的分词,输出格式为<url,item>。如果是标题页,则抓取出其中的链接,并在本机任务完成后与Core通信,将链接加入TaskQueue3中。
- 重复2中的过程知道达到了事先预定的链接层数。
- 监测网站内容更新时,每个Task_rankn以固定间隔时间监测自己的任务队列中是否有内容已经更新,如果有更新,则更新链接后,加入下一级任务队列,通过Core去调度。(这里做了一个假设,那就是每个新闻网站更新的都是它的标题页里的链接,而对于新闻文档页,一旦发布,则其链接将不会发生变化。)
下面是关于部分细节的讨论。
4.1.1无关链接
新闻网站通常有一些网页是不可能有新闻的,在获取文档集以及监测网站更新时,应该将这些链接排除掉。无关链接主要分为两类:一类是可以静态添加的,这一类主要是根据网站的结构推断出来的。另一类是必须动态添加的,这一类隐藏于网页当中,主要是网页中的广告链接。图4是人民网首页中的一些无关链接,黄色以下部分是的链接到别的网站的友情链接,以及网站声明一类的链接,这属于静态的无关链接,短时间内会保持不变;红色以上部分属于广告区域,其中的链接属于动态的无关链接,因为广告随时会增加和变化。

图4人民网首页的一些无关链接(来源:人民网)
静态无关链接,需要手动加入到排除链接集合,记作exceptLinkSet;而动态无关链接,则分两步来完成对其的排除,第一步对于标题页中链接,如果其链接地址不在人民网网站内,则不加入新任务队列中,直接排除掉,这能排除小部分的动态无关链接。图5是图4中红色以上广告区域的网页源码,可以看到该广告的链接地址在人民网网站内,广告获益的方式是通过重定向来记录广告效果。

图5一个网页广告链接的源码(来源:人民网)
与重定向有关的动态无关链接,先将其加入任务队列,等待在下一级任务去处理。在下一级任务获取链接后,通过判断返回的内容里取出的链接里是否有包含在人民网网站内的链接判断是不是广告链接(这样也能判断出一些如图片之类的资源链接)。判断出的无关连接加入到排除链接集合exceptLinkSet中。
4.1.2链接环路
网站的链接是存在环,为了正确的完成任务,需要保存已经访问过的链接。在Core中为每个Task_rankn保存一个排除链接集合exceptLinkSetn,这个链接集合的内容包括最开始静态添加的exceptLinkSet,及其父级别任务的链接排除集合,以及当前任务队列TaskQueuen中的链接。当获取一个标题页的所有链接后,首先排除不在网站内的链接,以及在exceptLinkSetn中的链接,然后将剩下的链接加入下一级的任务队列中。
4.1.3链接失效
网页链接失效,可以通过http响应Code来判断,这类链接也当作无关连接处理,加入exceptLinkSet。
4.1.4服务器反应缓慢
每一级链接处理完毕后都需要同步,如果由于服务器反应缓慢导致某个链接阻滞,将会导致系统阻滞,可以设置每个链接的连接和数据读取时间限制,即ConnectTimeOutLimit,以及ReadTimeOutLimit来防止。对于由服务器缓慢导致的任务失败,需要与Core通信,让其重新分配任务到别的机器上运行,同时Core需要设置一个任务尝试次数限制TaskTryLimit,当超过了这个限制时,只能说明服务器这时有问题,不能代表链接失效,此时将其忽略,不需要加入exceptLinkSet。
4.1.5文件名一致性
获取到的新闻文档,需要有一个全局的文件名。Core给每个机器一个全局的编号,机器获取的所有文档都以机器编号+任务级别+一级或者多级的文件编号命名,并以LinksSetn保存自己获取的文档的信息,格式为<url,lastModified,filename>。每个机器的LinksSetn最后需要同步到Core中。
4.1.6新闻信息解析
网站的网页分为标题页和内容页,新闻信息存在于内容页中,需要解析出来才能使用。可以根据网页的结构来区分标题页和内容页,然后根据内容页的结构解析出新闻内容。人民网的内容页中都有一个div标签的id属性为p_content,而新闻信息就存在与这个标签之中。如下图所示:
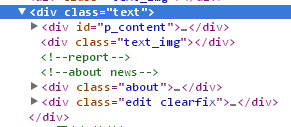
图6人民网一个新闻内容页的局部源码(来源:人民网)
解析新闻的标题,来源,发布时间,作者等信息时,也是采用同样的方法。但是也许是人民网出于安全性的考虑,各个新闻内容页的结构相似而不相同,就只能通过不断的发现新的结构来扩展解析模块的健壮性。所以对于解析失败的内容页,需要保存其链接,然后分析并修改解析模块,如此循环,直到解析模块的能力满足要求为止。
4.1.7实时监测
通过读取获取新闻文档集时保存的状态信息,以及修改链接层次的限制RankLimit,设置程序进入实时监测状态,并完成一些初始化操作。首先是去除各级任务队列中的包含在LinksSet里的链接;其次去除各级任务队列中的包含在exceptLinkSet中的链接,这是因为在获取新闻文档的过程中尽管发现的无关链接,能在下一级任务队列中使用,但是并没有及时更新到以上各级任务队列中。运行过程中这两个集合都会随着时间的推移不断扩充,需要定时做一下初始化操作,以减少监测任务。
当Core获取更新后,将其分发到下一级的Task_rank中。获取到的新的文档采用主动发送的方式送到分词模块。
为了便于维护,每个Task_rankn以及Core应该每隔间断时间保存自己的状态信息,同时整个运行模式应该能接受外部的消息,便于正确的停止的运行,以及下一次启动后能接着上次的状态运行。
4.2提取新闻关键词
模式初始化与正常运作时,分词模块的运行情况是一样的。区别仅在于,初始运作后时,模块收到的数据是最近一周的新闻文档,而正常运作时收到的是及时更新的新闻文档。分词模块的任务是将获取到的新闻内容转化为推送模块能使用的内容,数据处理过程如图:

图7获取新闻内容关键词的数据流程
上述图中黄色方框中的内容是需要发送到用户推送模块的内容。
4.3个性化推送
4.3.1目标
- 根据关键词判断出新闻的类别,然后依据新闻的关键词,新闻的类别,用户的类别这三者的对应关系,精确恰当的将新闻推送给用户。
- 充分发挥RSS格式的作用,简洁的语法方便客户端解析,却又能保持新闻文档原有的格式。
- 统计近一周出现在新闻中的关键词,以及它们出现的文档数量,以此来判断热点词,供新用户选择。
- 采集用户的行为属性,包括阅读时间,阅读地点,阅读内容所用时间,订阅的关键词等信息,用以对用户进行归类。
4.3.2难点分析
这个模块是整个模式中最重要的模块,它的准确度是整个模式的价值体现。个性化推送涉及到的主要难题有三:
- 基于关键词对新闻进行准确分类
- 基于采集到的用户行为信息对用户进行分类
- 新闻类别与用户类别之间的复杂映射
4.3.3新闻推送现状分析
对于新闻本体信息分类的方法已经有很多,这正是人们目前遵守的阅读方式――分类阅读。而对于用户行为属性的分类却几乎没有,一种简单的新闻推送方式是通过采集用户的历史浏览记录,并对历史记录分类,然后用户归纳到新闻的类别里,然后按照新闻的类别向用户推送新闻,这样导致的直接结果就是很多的新闻信息到了用户那里成了垃圾信息。
4.3.4用户行为信息采集
为了实现精确恰当的推送,必须充分发掘用户行为信息。为了精确的实现用户行为信息的分类,就必须先得深入采集足够多的用户行为信息,而不是简单的采集历史浏览记录。可以从以下这些方面考虑采集用户的行为信息:用户订阅的关键词,用户阅读新闻的方式(移动终端或者电脑),用户阅读新闻的起始和终止时间,用户阅读的新闻以及阅读该新闻所花费的时间,用户阅读新闻的地点信息(是否在移动中或者固定位置),用户阅读新闻所使用的网络,用户阅读新闻的先后顺序等等。用户订阅的关键词是最能直接表达用户兴趣点的信息;用户阅读的方式和他每天的阅读时间点能表达他对新闻的关注程度;从用户阅读的新闻内容以及阅读时所使用的时间可以判断出他对那一类新闻的关注程度;用户阅读新闻的地点通常表达着用户在什么情况下回去看新闻,从中能看出用户的阅读习惯;用户新闻阅读时所使用的网络,也能判断出用户看新闻的环境;用户阅读新闻信息的先后顺序间接表明了对不同新闻信息的关注程度不一样。这些信息虽然独立采集,但是并不能独立分析,只有将这些信息整合在一起,才能真正做到准确的发掘用户行为信息。比如用户的新闻阅读地点位置信息,只能表明他在这么一个地点阅读,但是不能表明这个地点是他的工作地方还是他路过的地方,这个可以根据网络使用情况来判断。
4.3.5用户行为信息分类
在采集了足够多的用户行为信息后,接下来就是根据这些信息来对用户进行准确分类。然而人并不像新闻本体一样是一个单一的个体,而是处于社会这个复杂的大环境中。人的行为异常复杂,要完成对人行为信息的分类,可以将下面这些交叉学科作为出发点考虑:社会学,新闻与传播学,统计学,心理学,概率学,公共关系学,伦理学,广告学,社会心理学,人类学等等,所有与人在社会中的思维过程有关的学科都需要加入考虑。从社会学的角度,可以根据用户行为信息判断用户对于自己身边事物的关注点,比如说是关注于社会事件还是仅仅关注生活娱乐等等。从新闻与传播学的角度,需要根据用户的行为信息判断出新闻对于该用户的影响程度,这个或许可以从他对于某个新出热点的关注度来测量。统计学是分类的核心,有了用户的各类行为信息,需要从各个社会学科的角度来综合这些信息并对用户进行分类。站在心理学角度来分析用户的行为信息,可以根据用户对于一个事件的不同报道的阅读时间来判断出其思想倾向,以及根据他的时间和地点可以判断出他是主动关注新闻,还是消极扫描。概率学的应用,可以根据用户行为信息,判断出他对于其他类新闻的接受程度,这个可以用于新热点推送。总之,和人的社会行为相关的各类社会学科都应该加入考虑,才能精确的做到用户分类,只有这样以人为核心才能做到新闻推送的准确恰当。
4.3.6结合用户类别对新闻分类
以往的新闻信息分类都是以新闻本体信息为核心的,如果能换加入对用户行为信息的考虑进行分类(注意这里是对新闻信息的分类,而不是对用户的分类),这样将能和用户分类结合得更加紧密,二者的关系也就更加精确。
4.3.7迭代训练模型
不管是对新闻信息的分类,还是对用户行为信息的分类,都不是一蹴而就的,需要建立知识模型,然后通过机器学习,不断训练,再迭代修改知识模型来完成对分类的精确化。这个过程需要采集大量的用户信息来判断推送的准确度,然后进一步调整和训练分类,是一个迭代进化的过程,必须要有足够多的新闻信息,加上足够多的用户行为信息经过长时间的训练才能得到令人满意的模型。
5方案讨论
上述的方案只是针对基于关键词的个性化新闻推送的一个初步解决方案,它的意义在于阐述以人为核心的基于关键词的新闻推送方式的可行性以及预见性。设计中难免有不妥之处,这需要根据实际运行环境作调整。比如网站监测的数据可靠性的问题。设计中只是提到将数据以文件的格式保存,然而数据到底以什么格式保存,以及以集中式保存还是分布式保存都是各有优劣。以文件保存,主要是方便于系统初始化时用hadoop完成分词统计。对于之后的数据可以才去集中式的方式保存,但是这将付出网络通信代价。如果采用分布式存储,数据如何冗余保存,有事需要进一步考虑的问题。
6结论
通过全篇对于新闻推送现状的讨论,以及利用初步解决方案对以人为核心的基于关键词的个性化新闻推送这种新模式的解读,可以看到这种新闻推送模式的可行性和预见性。人民网本着权威新闻的地位,拥有新闻资源丰富,用户信息量足够等先天优势,如果能积极拥抱大数据时代,充分把握这个难得充满挑战的机遇,尽早完成对于新闻信息和用户行为信息的精确处理和整合,然后给用户提供精确恰当的服务,必将使得人民网成为新闻传播的引导者,并奠定其在新闻门户中的不可动摇的地位。
7其他参考文献
[1]段春霆.基于RSS的个性化新闻推送系统设计与实现[J].科技资讯,2006,(18).
[2]申超,王健.RSS技术在新闻推送系统中的应用研究[J].计算机工程与应用,2006,(17).
[3]王立霞,淮晓永.基于语义的中文文本关键词提取算法[J].计算机工程,2012,38(01):1-4.
[4]cooling搜索.个性化新闻推送.:http://search.ape-tech.com/solution_news.htm.
[5]itwriter.Twitter开设个性化突发新闻推送账号.: http://news.cnblogs.com/n/190054/.
[6]张华平.NLPIR汉语分词系统.http://ictclas.nlpir.org/.
[7]Orisun.文章关键词提取算法. http://www.cnblogs.com/zhangchaoyang/articles/2377385.html.
[8]关于新闻阅读的一个知乎问答.http://www.zhihu.com/question/20123626.











 恭喜你,发表成功!
恭喜你,发表成功!

 !
!






















