 分享到人人
分享到人人[摘要] 本文运用内容分析法,以腾讯2011年两会专题微博(N = 900)为样本,对微博主题、用户身份以及两者的交互关系进行了研究。总体说来,微博用户的身份与主题显著相关。其中普通百姓﹑媒体和知名人士着重反映问题、传播信息﹑提供建议﹑评价时政和调侃时局,两会代表主要在传播信息和提供建议。相比之下,政府机构或官员与非政府组织微博议政的参与程度不高。研究结果说明微博为中国网民扩展了议政平台,促进了社会群体之间的沟通。
[关键词] 微博议政; 微博主题; 用户身份
一、研究问题综述
本文选取了2011年两会召开期间的腾讯微博作为样本,着重探讨四个问题:一、腾讯2011年两会专题微博的主题;二、腾讯2011年两会专题微博的用户身份;三、同类主题中,不同身份用户的比例是否有明显差异;四、同类用户中,不同议政主题的比例是否有明显差异。
研究对象之所以没选新浪微博,是因为截止到本研究结束时,新浪微博只能就某一主题提供最多50页的搜索结果,且无法任意按照某一特定日期进行搜索,此外,新浪微博不能按照帖子回复条数的多少进行降序排列,使研究无法对最具代表性的帖子进行取样,而腾讯微博克服了这些不足。
二、研究方法
本研究通过焦点小组访谈进行取样,用内容分析法对数据进行分析。具体步骤如下。
1.确定样本
在腾讯微博搜索框里输入关键词“两会”,将微博发布时间限定在2011年3月3日到14日(即2011年两会召开期),类型选定为“原创”,然后进行搜索,会得出284,112条微博,样本数量过大,难以分析。此外,一些微博内容过于情绪化,回复量少,代表性不强。因此,决定进一步缩小研究样本量。为了解用户浏览微博的习惯,研究者采用焦点小组访谈的方法来确定每日所选微博的页数。该方法在社会科学领域应用广,信度高,通常采用小型座谈会的形式,由一个经过训练的主持人组织小组成员进行讨论,以获取收集数据的方式和内容。①
研究者在腾讯QQ上建了一个专属讨论群,选取了21位年龄、性别、地域和职业各异的微博用户,将他们随机分为两组,约好时间同时上线,说明访谈流程,然后逐一询问通常情况下平均浏览微博的页数。受访者的回答从第1页到第5页不等,回答第3页的最多。为使取样量更具涵盖性,本研究取最大数字5作为每日微博的选取页数。从2011年3月3日到14日,在“两会”的关键词搜索结果中,研究者将微博按照回复数目由多到少排列,选取每天的前5页微博。由于腾讯微博每一页包含15条微博,5页即包含75条微博,两会召开的12天里,共有900条微博被选作研究样本。
2.编码分类
在本研究中,每一条微博是一个分析单位。研究者对微博的主题和用户进行编码分类,以牛津词典有关定义为基础,为每个帖子的主题和用户设定了操作定义(表1及表2),避免定义重合。
两位受过训练的编码员随机选取100条微博(11.1%),根据操作定义对每条微博的主题和用户编码,进行先期信度测试。微博主题被分成了8类,分别是反映问题、评价时政、提供建议、调侃时局、传播信息、征求反馈、诉求意愿和其他主题。微博用户包含7类,分别是普通民众、媒体、知名人士、政府机构及其官员、两会代表、非政府组织和其他用户。
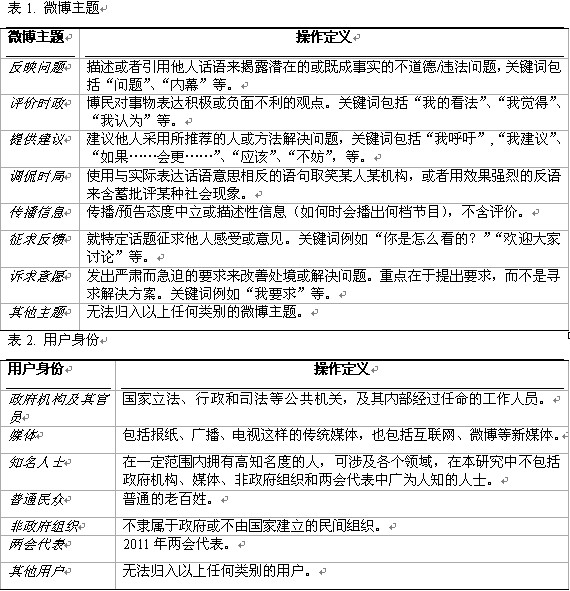
在所研究的帖子中,一些微博的主题不止一个,考虑到微博的长度,我们只选取其中最突出的主题。经SPSS测试,两个编码员在微博主题和用户身份的Kappa值分别是0.962和0.954,即这两项的交互信度分别是96.2%和95.4%,误差率都小于0.05,信度检验合格(百分比一致性= .96; Scotti’s Pi= .95)。两人编码的不同之处,通过协商,最终达成一致。
 |

































