 分享到人人
分享到人人

2012年度“人民網優秀論文獎”獲獎名單10月30日揭曉,北京郵電大學計算機學院劉健、於淼同學的作品《海量新聞信息處理中的中文分詞算法研究》獲得人民網優秀技術課題二等獎,以下是論文全文:
一、研究題目現實意義
人民網作為國際互聯網上最大的綜合性網絡媒體之一,對信息的時效性把控也越來越高。隨著WEB 3.0時代的到來,門戶網站新聞媒體已經不再是互聯網內容的主要來源,SNS平台,微博,博客,論壇,點評網等每天會產生海量內容(UGC),而每日的熱點,輿情也蘊含於其中。面對日益增加的海量數據,如何從海量數據中挖掘出熱點問題,從而迅速把握熱點動態,網絡輿情,也成為人民網非常關心以及亟待解決的問題。
為應對互聯網的海量數據處理,雲計算應運而生。基於現有的雲框架,人民網可用現有的網絡數據爬取技術將海量互聯網數據收集到集群當中,運用雲計算技術進行數據的抽取與挖掘。可以說雲計算已經基本可以滿足海量數據給人民網帶來的數據存儲以及運算方面的挑戰。但是我們知道,分析中文的信息,除了要有良好的數據處理能力,還有一個非常重要的方面就是中文的自然語言處理能力。
我們知道,基於網絡輿情監控風險評估系統的算法是基於WEB文本挖掘一些基本的模型與算法:如TF-IDF模型,關聯規則的Apriori算法,監督學習中SVM算法等等。然而這些算法能用於中文文本挖掘的先決條件就是有一個良好中文的分詞模塊,所以中文分詞作為風險評估,網絡輿情的基礎工具,角色十分重要。
眾所周知,中文與英文書寫方面的最大不同在於,英文以詞為單位,而且每個詞之間有空格隔開,所以英文分詞非常簡單。但是中文是以字為單位,詞與詞之間無空格,所以中文分詞要有自己獨立的一套方法。
二、社會化新聞中的中文分詞算法
當前計算機技術大氣候下,技術條件非常成熟。一方面各大門戶網站面臨激烈的市場競爭,社會和用戶對信息獲取的准確度和熱度的要求日漸嚴格和苛刻,另外一方面,由於客戶業務增長和歷史積累所導致的海量業務數據,網絡用語、機構簡稱等新名詞不斷增加,對分詞技術提出了新的挑戰。
社會化新聞一直是人民網關注的重點問題,分詞技術也成為人民網風險評估系統中的重要組成部分。結合人民網的實際情況,在對新聞等內容的分詞當中主要存在以下幾點難題:分詞歧義問題,未登錄詞的處理,以及專業分詞詞典的構建,比如在社會化新聞中經常會出現一些人民或機構名詞,如:“王瑜琿任長沙市委組織部副部長”,“湄公河聯合執法動態”等,其中“王瑜琿”,“湄公河”這些詞可能在我們現有的詞庫中不存在,很難被切分出來。我們根據以往的研究積累,針對人民網對於社會化海量新聞的分析需求,有針對性的在文中提出了幾種分詞算法。不僅在原理上做了正確論述,由理論應用到分詞算法上也有詳細描述。通過研究,我們認為基於隱馬爾科夫模型(HMM)的改進模型多重隱馬爾科夫模型(CHMM)在分詞算法上更為出色,更適合為風險評估系統提供服務。
與此同時,結合人民網風險評估系統,我們認為具有預警意義的詞應該是名詞動詞或者形容詞。對於一些代詞如:“我們”,助詞“的”等可以進行過濾。所以我們的分詞模塊可以通過詞性過濾,來進行關鍵詞提取,使依據詞的評估更精確。
不僅如此,風險評估系統中的詞多數為新詞,我們提供新詞添加功能,以便使分詞效果更加准確。具體方案將在第六部分論述。
在理論研究的同時,我們對本文提出的多重隱馬爾科夫模型算法進行實現,並結合了詞性過濾與添加新詞的功能,使分詞取得了較好的效果,從而使理論結合了實際,為人民網的分詞技術的優化提供了可靠的方案。
三、技術難點解析
分析人民網的媒體類型特點和海量社會化新聞的特點以及風險評估系統的需求,我們初步總結出了以下三點亟待解決的分詞難題:
3.1交集型歧義:
對字串漢字串AJB,如果滿足AJ、JB同時為詞(A、J、B分別為漢字串),那麼字串AJB被稱作交集型切分歧義。例如:“結婚的與尚未結婚的”,應該分成“結婚?的?和?尚未?結婚?的”,也可以分成“結婚?的?和尚?未?結婚?的”。
3.2組合型歧義:
如果漢字串AB滿足A、B、AB同時為詞,那麼AB被稱作組合型切分歧義。例如:“這扇門的把手”中的“把手”就是一個詞,“把手抬起來”的“把手”就必須拆開﹔
3.3未登錄詞識別:
未登錄詞往往與其前后的字詞交叉組合,不僅增加了自身切分的難度,而且嚴重地干擾了相鄰詞的正確切分,從而大大地降低了詞法分析乃至整個句子分析的正確率。
在海量社會新聞的文本當中,未登錄詞問題尤為重要。未登錄詞主要考慮以下幾個方面:中國人名,地名,機構名,縮略語,新詞。
所以,我們提出的方案,必須要能較好解決以上問題,並兼顧人民網對於海量社會化新聞的處理以及風險輿情的監測。我們認為基於HMM改進模型算法可以較好的為人民網解決分詞技術難題,並為風險評估系統提供優質服務。
四、中文分詞算法設計:
中文分詞方法可粗略分為兩大類:第1類是基於語言學知識的規則方法,如:各種形態的最大匹配、最少切分方法、以及綜合了最大匹配和最少切分的N-最短路徑方法。第2類是基於大規模語料庫的機器學習方法,這是目前應用比較廣泛、效果較好的解決方案。用到的統計模型有N元語言模型、信道-噪聲模型、最大期望、隱馬爾科夫模型等。由於人民網海量新聞種類繁多,而且每日新名詞產生量巨大,所以我們認為機械分詞配合統計模型方法進行設計,並在其中加入人工干預,用人工與智能相結合的方法,可以達到比較好的效果。
4.1基於字符串匹配的算法
基於字符串匹配的分詞方法又稱為機械分詞方法。它的分詞策略簡單的說就是將帶切分字串與分詞詞典中的詞進行匹配,如果能夠在分詞詞典中找到該字串,則進行切分,否則不予切分。基於字符串匹配的分詞方法主要有正向最大匹配算法(Forward MM, FMM)、逆向最大匹配算法(Backward MM, BMM)、雙向最大匹配算法(Bi-directional MM)、最小匹配算法(Minimum Matching)。
下面把正向最大匹配法(FMM)作為機械分詞法的代表,對其過程詳細介紹,流程圖如圖3-1所示。
1.初始化待切分字串S1,及輸出字串S2,S2為空﹔
2.找出分詞詞典中最長的詞條,並設該詞條所含漢字個數為I﹔
3.取被處理文本當前字符串S1中的I個字作為匹配字段,查找分詞詞典。若詞典中有這樣的一個I字詞,則匹配成功,將匹配成功的詞W賦給S2並在該匹配字段后加一個切分標志,然后繼續處理接下來的句子﹔
4.如果分詞詞典中查找不到這樣的一個I字詞,則匹配失敗﹔
5.上步中的匹配字段去掉最后一個漢字,I--﹔
6.重復步驟3-5,直到能夠在詞典中進行匹配,並將匹配的字串成功切分﹔
7.分子切分結束,輸出S2。
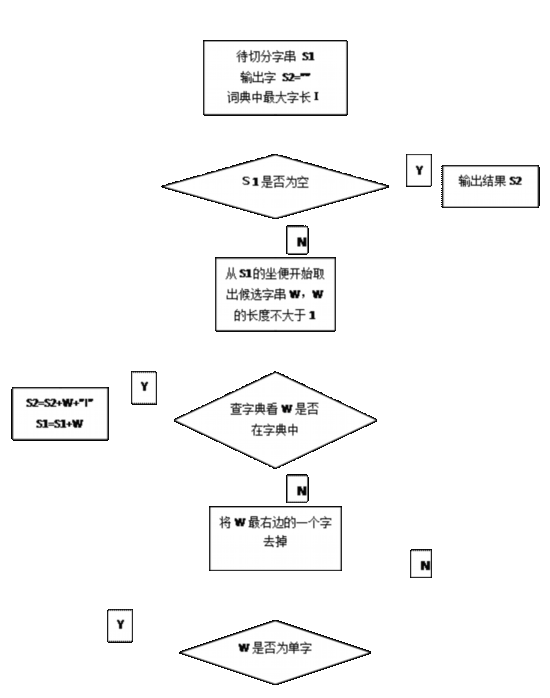
圖4-1
正向最大匹配法的優點就是易於實現而且分詞速度也比較快,但是對交叉歧義和組合歧義沒有特別好的解決辦法,因為它只是根據詞典進行機械的切分。經統計,在詞典完備,沒有任何其他知識的條件下,錯誤切分率1/169,但是有個完備的詞典是不可能實現的,該方法往往不單獨使用,而是與其它方法配合使用。
我們可以建立一個特殊規則表來改進機械分詞的性能,例如:“會診”后面接“斷”、“療”、“脈”、“治”時要把“會”要單獨切出,這樣可以對分詞歧義有一定意義上的修正。還可以維護一張不單獨成詞的字表:如民,偉,塵等。但是維護特殊規則的表的方法會花費大量的人力資源,而起需要不斷更新規則,更可能會出現規則的沖突。
4.2基於大規模語料庫的統計模型算法研究:
在分詞算法的研究中,基於統計的分詞方法和機械分詞法幾乎是交替處於領導地位。時至今日,基於統計的分詞方法越來越受到學者的青睞。基於統計的分詞發放有兩個基本的理論模式。
一、利用漢字之間結合關系的緊密程度來判定那些字符串應該結合成詞。這種統計的方法可以在分詞過程中脫離對詞典的依靠。詞是穩定的字的組合,因此在上下文中,相鄰的字同時出現的次數越多,就越有可能構成一個詞。因此字與字相鄰共現的頻率或概率能夠較好的反映成詞的可信度。可以對語料中相鄰共現的各個字的組合的頻度進行統計,計算它們的互現信息。這種方法的優勢是不需詞典,對詞典已收錄的詞和未收錄的有相似的解法。但也無法有效實現對長於二字的詞的延伸處理。
二、模式二的原理是通過計算語料中字符串的分布的強度,包括其重復出現的概率和環境,以此作為該字符串是否應被分成詞的一句。簡而言之,這種模式在尋找語料中最可能成詞的字符串。模式二的優勢在於對詞典已收錄和未收錄的詞均使用。並且對於同一字符串,在不同的語料中,有著不同的分布強度,自然可以得到不同的分析結果。這樣對於歧義字符串完全可以達到理想的有兩個或以上分析結果。
我們以二元的Bi-Gram的基本原理為例做說明:對於任意兩個詞語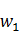 ,
,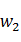 ,統計在語料庫中詞語后面恰好是的率P(,)。於是產生一個巨大的二維表。再定義一個句子的劃分方案的得分為P(?,)·P(, )·…·P(
,統計在語料庫中詞語后面恰好是的率P(,)。於是產生一個巨大的二維表。再定義一個句子的劃分方案的得分為P(?,)·P(, )·…·P(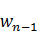 ,
,  ),其中, , …, 依次表示分出的詞。利用動態規劃求出得分最高的分詞方案。
),其中, , …, 依次表示分出的詞。利用動態規劃求出得分最高的分詞方案。
4.2.1隱馬爾科夫模型(HMM)
4.2.1.1基本原理論述:
隱馬爾可夫模型是在馬爾可夫模型的基礎上發展而來的,它是為了解決我們觀察的事件往往並不是與狀態一一對應而只是通過一定的概率分布相聯系的問題而提出的。HMM是一個雙重隨機過程,一個是具有一定狀態數的馬爾可夫鏈,這是基本的隨機過程,它描述狀態的轉移﹔另一個隨機過程描述狀態和觀察值之間的統計對應關系。其中模型的狀態轉換過程是不可觀察的,因而稱之為“隱”馬爾可夫模型。一個HMM可能用一個五元組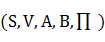 來表示,其中:
來表示,其中:
(1) S代表一組狀態的集合,S={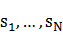 },其中的狀態數為N,並用
},其中的狀態數為N,並用 來表示t時刻的狀態。
來表示t時刻的狀態。
(2) V表示一組可觀察符號的集合,V={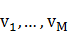 },M是從每一個狀態可能輸出的不同觀察值的數目。
},M是從每一個狀態可能輸出的不同觀察值的數目。
(3) A代表狀態轉移概率矩陣,A={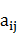 },其中
},其中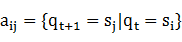 ,
, ,這是個N行N列的矩陣,表示從狀態
,這是個N行N列的矩陣,表示從狀態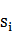 轉移到狀態
轉移到狀態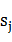 的概率。
的概率。
(4) B表示可觀察符號的概率分布, },
},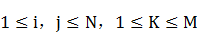 表示在狀態輸出觀察符號
表示在狀態輸出觀察符號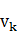 的概率。
的概率。
(5) 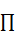 表示初始狀態的概率分布,
表示初始狀態的概率分布,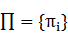 ,其中
,其中 ,它表示在時刻1選擇某個狀態的概率。
,它表示在時刻1選擇某個狀態的概率。
一個確定的隱馬爾可夫模型,其狀態數和每個狀態可能輸出的觀察值的數目都是可以確定的,因此可以用(A,B,)來表示模型的參數。其中,由,A描述馬爾可夫鏈,產生的輸出為狀態序列,記為Q,表示第t次轉移的源狀態﹔B則描述隨機過程,產生的輸出為觀察值序列,記為O,表示第t次轉移的輸出。
4.2.1.2基於HMM模型的分詞策略:
中文分詞的N元統計模型中,將信號源抽象為隱馬信號源,也就是採用了二元統計模型。而這時的Markov模型中的狀態是我們觀察不到的。而對應正確的切分詞的序列就是此隱馬模型的真實序列,而被分詞的文本則是此隱馬爾柯夫鏈的觀測值。則在二元統計模型中,中文分詞的過程就轉化已知隱馬模型觀測值(文本)求解其真實序列的值(分詞結果)。記錄Markov信源產生的詞的序列C的某個可能分詞結果為W=(,…,),W對應的詞的隱狀態序列C=(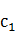 ,…,
,…, )。我們選擇最優的隱狀態序列作為我們的分詞結果W*:
)。我們選擇最優的隱狀態序列作為我們的分詞結果W*:
則W#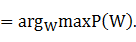 4-1-1
4-1-1
利用貝葉斯公式進行展開,得到
W#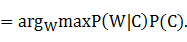
將詞類看做狀態,詞語作為觀測值,利用一階HMM展開,得
W#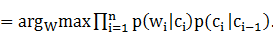 4-1-2
4-1-2
(其中,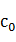 為句子的開始標記BEG,下同)
為句子的開始標記BEG,下同)
為計算方便,常用負對數來計算,則
W#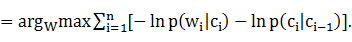 4-1-3
4-1-3
對W*求解的問題則轉化為求此問題的最小值。對於已收入核心詞典的詞,p( |
|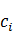 )=1分詞過程中隻考慮未錄登詞的p(|)值。
)=1分詞過程中隻考慮未錄登詞的p(|)值。
4.2.2條件隨機場模型(CRF)
4.2.2.1 CRF基本原理論述
條件隨機場模型(Conditiional Random Fields,CRFs)是一種建立切分和標注序列數據概率模型的框架,它用特征函數的方式綜合使用各種互相影響的語言特征,集合了最大熵模型和HMM模型的特點,回避了傳統HMM方法處理長距離關聯的不足和MEMM等模型中的標注偏置問題。
CRF是一種無向圖模型,對於指定的節點輸入值,能夠計算指定的節點輸出值上的條件概率。其訓練目標是使得條件概率最大化。線性鏈是CRF中常見的特定圖結構之一,它是由指定的輸出節點順序鏈接而成。定義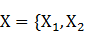 ,…..,
,…..,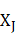 }定義為給定的輸入觀測序列,即無向圖模型中t個輸入節點上的值(如一個中文詞序列)﹔定義
}定義為給定的輸入觀測序列,即無向圖模型中t個輸入節點上的值(如一個中文詞序列)﹔定義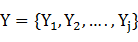 為一個長度與x相等的狀態序列,即無向圖中t個輸出節點上的值。參數
為一個長度與x相等的狀態序列,即無向圖中t個輸出節點上的值。參數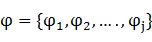 的線性鏈CRF把給定輸入序列x得到的狀態序列y的條件概率定義為:
的線性鏈CRF把給定輸入序列x得到的狀態序列y的條件概率定義為:
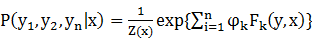 4-2-1
4-2-1
Z(x)是一個范化因子,使得在給定輸入上的所有可能的狀態序列的概率之和為1﹔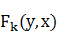 表示一個特征函數,通常取布爾值,
表示一個特征函數,通常取布爾值,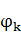 是訓練中得到的,與每個特征
是訓練中得到的,與每個特征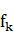 相關的權重參數,它的取值反映了特征函數所代表的事件發生的可能性。
相關的權重參數,它的取值反映了特征函數所代表的事件發生的可能性。
4.2.2.2.CRF分詞策略
一、標記問題解決分詞:就是將詞語開始和結束的字標記出來,就能對一個句子完成分詞,假設使用兩個標記B (開始),E(結束)對句子進行處理,如:“民主是普世價值”,民B主E是B普B世E價B值E, 這樣標記明確,分詞結果就明確了。
二、如何找到最好的標記結果:知道如何用標記的方式解決分詞,那麼怎麼為一個句子找到一個最好的標記序列呢,CRF為這樣的問題提供了一個解決方案,對於輸入序列(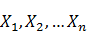 )(對於分詞,就是那個句子),求這個輸入序列條件下 某個標記序列(
)(對於分詞,就是那個句子),求這個輸入序列條件下 某個標記序列(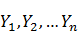 )的概率極值。
)的概率極值。
三、解碼過程:
CRF的公式:
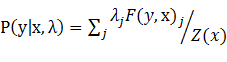 4-2-2
4-2-2
設使用4標記,B-開始,O-單獨成詞,M-詞語中間的字,E-結束,特征:一元特征,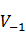 當前字的前一個字,
當前字的前一個字,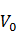 當前字,
當前字,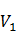 當前字的后一個字二元特征,各標記間的轉移特征。
當前字的后一個字二元特征,各標記間的轉移特征。
例如:
民 主 是 普 世 價 值
B BBBBBB
O OOOOOO
M MMMMMM
E EEEEEE
運用Viterbe解碼算法,即在以上由標記組成的數組中搜索一條最優的路徑。對於每一列的每一個標記,我們都要計算到達該標記的分數,這個分數由三部分組成,它本身的一元特征權重W,它前面一個字標記的路徑分數PreScore,前面一個字標記到當前標記轉移特征權重TransW。
1. 計算第一列的分數(score),對於,‘民’來說,我們要算 B,O,M,E的Score,因為是第一列,所以PreSocre和TransW都是0,就不用計算,隻需要計算自己的一元特征的權重:對於標記,B,我們計算它的Score,記為S1B= B=w(nul民,B)+w(民,B)+w(民,B,主)。
B=w(nul民,B)+w(民,B)+w(民,B,主)。
這些特征的意思是:(null,民,B),當前字為‘民’標記為B,前面一個字為空,(民,B):當前字為‘民’,標記為B,(民,B,主):當前字為'民',標記為B,當前字的后一個字為‘主’。特征的權重都是在訓練時得到的。對於標記,O,M,E,一樣要計算W1O,W1M,W1E,從而得到分數S1O,S1M,S1E。
2.對於第二列,首先要計算是每個標記的一元權重W2BW2O,W2M,W2E對於B,到達該標記的最大分數為:S2B=Max((v(BB)+S1B),(v(OB)+S1O),(v(MB)+S1M),(v(EB)+S1E))+W2B其中v(BB)等為B到B的轉移特征的權重。這個也是由訓練得到的。同樣對於第二列的O,M,E也要計算S2O,S2M,S2E。
3.一直計算到最后一列,‘值’字的所有標記,得到S7B,S7O,S7M,S7E.比較這四個值中的最大值,即為最優路徑的分數,然后以該值的標記點為始點 回溯得到最優路徑。
4.2.3 基於HMM模型的分詞算法改進策略:
本文經過調研找到了一種基於多重隱馬爾科夫模型(CHMM)的方法,旨在將漢語分詞、切分排歧、未登錄詞識別、詞性標注等詞法分析任務融合到一個相對統一的理論模型中。
CHMM實際上是若干個層次的簡單HMM的組合,各層HMM之間共享一個切分詞圖作為公共數據結構;每一層隱馬爾可夫模型都採用N-Best策略,將產生的最好的若干個結果送到詞圖中供更高層次的模型使用。

圖4-2
首先,在預處理的階段,採取N-最短路徑粗分方法,快速地得到能覆蓋歧義的最佳N個粗切分結果﹔隨后,在粗分結果集上,採用低層隱馬模型識別出普通無嵌套的人名、地名,並依次採取高層隱馬模型識別出嵌套了人名、地名的復雜地名和機構名﹔然后將識別出的未登錄詞以科學計算出來的概率加入到基於類的切分隱馬模型中,未登錄詞與歧義均不作為特例,與普通詞一起參與各種候選結果的競爭。最后在全局最優的分詞結果上進行詞性的隱馬標注。
原子切分是詞法分析的預處理過程,主要任務是將原始字符串切分為分詞原子序列·分詞原子指的是分詞的最小處理單元,在分詞過程中,可以組合成詞,但內部不能做進一步拆分·分詞原子包括單個漢字,標點以及由單字節、字符、數字等組成的非漢字串。如“2012.9人民網蓬勃發展”應切分為:2012.9\人\民\網\蓬\勃\發\展。
在分詞歧義問題上我們採取的是N-最短路徑的切分排歧策略。其基本思想是在初始階段保留切分概率P( W)最大的N個結果,作為分詞結果的候選集合。在未登錄詞識別、詞性標注等詞法分析之后,再通過最終的評價函數,計算出真正最優結果。實際上,N-最短路徑方法是最少切分方法和全切分的泛化和綜合。
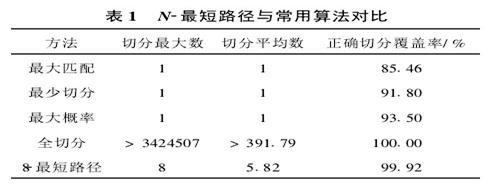
圖4-3
在未登錄詞識別問題上,我們對初始切分得到的各個詞按照其在未登錄詞識別中的作用進行分類,並將詞所起的不同作用稱為角色。

圖4-4
對於一個給定的初始切分結果W=(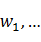 ,),在一個角色集合的范疇內,假定R=(
,),在一個角色集合的范疇內,假定R=(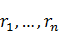 )為C的某個角色序列。我們取概率最大的角色序列R#作為最終的角色標注結果。和第3節隱馬分詞的推導過程類似,我們最終可以得到
)為C的某個角色序列。我們取概率最大的角色序列R#作為最終的角色標注結果。和第3節隱馬分詞的推導過程類似,我們最終可以得到
R#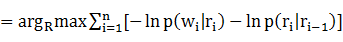
R#可以通過Viterbi算法[26]選優得到﹔
復雜地名和機構名往往嵌套了普通無嵌套的人名、地名等未登錄詞,如“張自忠路”、“周恩來和鄧穎超紀念館”。對於這種嵌套的未登錄詞,我們的做法是:在低層的HMM識別過程中,先識別出普通不嵌套的未登錄詞,然后在此基礎上,通過相同的方法採取高層隱馬模型,通過角色標注計算出最優的角色序列,在此基礎上,進一步識別出嵌套的未登錄詞。
基於類的隱馬分詞算法:本算法處於CHMM的第2層,也就是在所有的未登錄詞識別完成后進行。首先,我們可以把所有的詞分類:
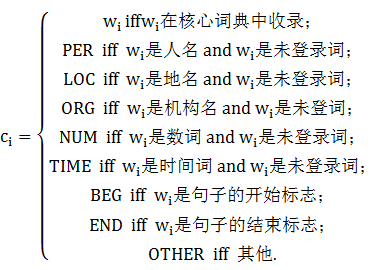
其中,核心詞典中已有的每個詞對應的類就是該詞本身。這樣假定核心詞典中收入的詞數為|Dict|,則我們定義的詞類總數有:|Dict|+6。給定一個分詞原子序列S,S的某個可能分詞結果記為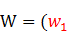 ,…,
,…,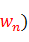 ,W對應的類別序列記為
,W對應的類別序列記為 ,同時,我們取概率最大的分詞結果W#作為最終的分詞結果。則
,同時,我們取概率最大的分詞結果W#作為最終的分詞結果。則
W#
利用貝葉斯公式進行展開,得到
W#
將詞類看做狀態,詞語作為觀測值,利用一階HMM展開,得
W#
(其中,為句子的開始標記BEG,下同)
為計算方便,常用負對數來計算,則
W#
根據類 的定義,如果
的定義,如果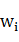 在核心詞典收錄,可以得到=,因此,
在核心詞典收錄,可以得到=,因此,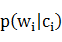 =1。在分詞過程中,我們隻需考慮未登錄詞的。在圖2中,我們給出了“毛澤東1893年誕生”的二元切分詞圖。最終所求的分詞結果就是從初始節點S到結束節點E的最短路徑,這是典型的最短路徑問題,可以採取貪心算法,如Dijkstra算法快速求解。
=1。在分詞過程中,我們隻需考慮未登錄詞的。在圖2中,我們給出了“毛澤東1893年誕生”的二元切分詞圖。最終所求的分詞結果就是從初始節點S到結束節點E的最短路徑,這是典型的最短路徑問題,可以採取貪心算法,如Dijkstra算法快速求解。
五、方案流程與評估方法
5.1 算法實現流程與改進策略
如5-1圖所示,將待處理文檔通過多重隱馬爾科夫分詞模塊兒經過,原子切分,未登錄詞識別及詞性標注得到初步的分詞結果。再根據分詞結果,結合人工審核的方式將應該分到一起的詞加入詞典,以便優化分詞效果。得到初次的分詞結果再根據詞性過濾模塊兒將名詞、動詞、形容詞過濾出來,得到關鍵詞,從而較好濾除噪聲。
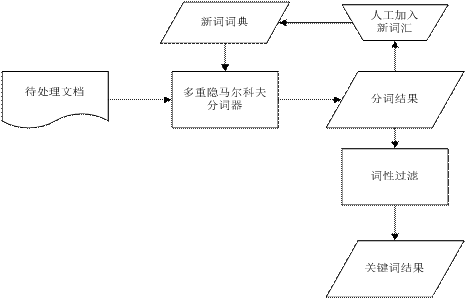
圖5-1
5.2 分詞效果評估方案:
我們可以才用人工標注的方法進行樣本文本的分詞,再用分詞器進行切分,然后比對二者差別,從而評估分詞器效果。可以借鑒檢索系統的評價,具體主要從以下精確度與召回率兩個方面來進行評價。

對應於分詞系統,主要用到精確度與召回率。其對應含義為:
Tp 分詞正確的數量﹔ Fp 分詞錯誤的數量﹔ Fn 未正確分詞的句子數量
注:一句話可有多個分詞結果。
六、結語
綜上所述,在中文分詞算法方面基於大規模語料庫的統計算法在是現有方法當中表現比較出色的一個。由於中文詞法的復雜性,完全依靠計算機智能分詞很難實現,所以在智能分詞環節引入人工干預,由人來添加新的詞匯往往會收到比較好的效果。在人民網的風險評估系統中,分詞模塊兒作為基礎工具意義重大,希望我們能共同探索,發現更好的分詞方法。
我們實驗室的項目,立足於市場和應用的基礎研究,為北京市某政府單位提供了垂直搜索引擎服務,廈門移動的數據挖掘系統也是我們合作的一個方向,其中分詞基礎都是處於一個基礎研究方向。我們期待進一步的合作。



































