 分享到人人
分享到人人摘 要:我國網絡期刊文獻大都採用PDF格式,且以文本型(矢量模式)為主,但也有部分為圖片型(光柵模式)PDF文獻。圖片型PDF文獻無法復制、搜索、取詞,也不支持在線實時檢索、學術不端檢測等功能。利用Adobe Acrobat Professional 10.0可對掃描或其他方式生成的圖片型PDF文獻進行頁面裁剪、OCR文本識別及頁面校正,從而可以獲得頁面整潔、端正的文本型PDF文獻。
關鍵詞:Adobe Acrobat Professional 10.0﹔OCR文本識別﹔文本型﹔圖片型
我國網絡期刊出版採用的文件格式主要有CAJ、PDF和HTML三種[1],其中大多數為PDF格式[2]。PDF是世界上期刊網絡版通用格式[3],我國的中國知網(CNKI)和國家科技圖書文獻中心(NSTL)也都提供PDF格式的期刊文獻。生成PDF文檔的常用方法包括通過其他軟件中轉和通過虛擬打印機。目前期刊編輯部廣泛使用北大方正書版排版軟件,可以直接或間接生成文本型PDF文獻,其文字為矢量模式,可以進行選擇復制、搜索查找、金山詞霸取詞等操作。但在缺少原始電子文件時,則需以掃描樣刊的方式生成圖片型PDF文獻。圖片型PDF文件整個頁面為一個光柵圖像,其中的文字不能被選中 [4-5],不僅無法復制、搜索、取詞,也不支持在線實時檢索、學術不端檢測等功能,也常會出現邊緣有多余文字以及頁面不正等情況,從而影響到讀者對文獻的閱讀利用和數據庫系統的正常運行。本文利用Adobe Acrobat Professional 10.0,以自國家科技圖書文獻中心(NSTL)下載的英文文獻“Relative measure index: a metric to measure the quality of journals”作為示例,對掃描(也可以是其他方式轉換)生成的圖片型(光柵模式)PDF文獻進行裁剪,通過OCR文本識別轉換為文本型(矢量模式),並同步對頁面進行校正。
一、PDF文件頁面裁剪
用Adobe Acrobat Professional 10.0打開所處理文獻,首先對頁面進行裁剪,裁剪需要逐頁進行,而對於文本識別、啟動注釋等,可以整篇同時完成。
圖1為所處理文獻的首頁,該文獻為掃描生成的圖片型PDF文件,無法進行文字選中、復制、搜索(查找)、翻譯取詞等操作,整篇文獻頁面橫置,頁面邊緣有多余文字。
點擊右上角“工具”按鈕,打開“工具”窗格,選擇“頁面”→“裁剪”路徑(如圖2所示)。用出現的十字形光標選擇裁剪區域(如圖3所示),在選擇區域內雙擊鼠標右鍵,出現“設置頁面框”對話框(如圖4所示),確定即可完成裁剪﹔這一步也可以單擊鼠標右鍵,點擊“設置頁面框”命令,這時即直接將裁減框外的頁面裁剪掉。

圖1 所處理的掃描生成PDF文獻(首頁)

圖2 工具—頁面—裁剪 圖3 選擇裁減區域
工具窗格也可以通過菜單欄中的“視圖”→“工具”路徑打開,但不如通過工具窗格打開操作便捷、界面友好。
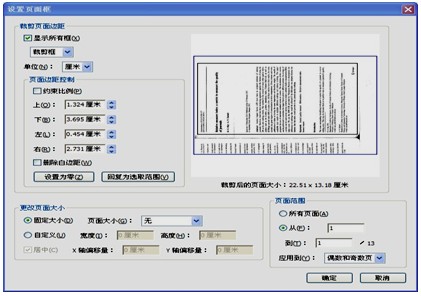
圖4 “設置頁面框”對話框二、將圖片型PDF文件轉換成文本型PDF文件
打開“工具”窗格,通過“識別文本”→“在本文件中”路徑(如圖5所示),打開“識別文本”對話框(如圖6所示),點擊“編輯”按鈕,出現“識別文本-一般設置”對話框(如圖7所示),設置OCR識別的主要語言,根據筆者觀察選擇中文或英文對識別效果沒有影響,識別准確率都很高,但對生成的文本型PDF進行復制、粘貼操作中,如果設置語言與轉換語言不一致,則可能出現亂碼。分辨率選擇300dpi,設置完成后確定,即可將圖片型轉換為文本型,並同步進行頁面校正,將傾斜的頁面轉正,也可將橫置頁面轉換為豎立﹔通過菜單“文件”→“另存為”→“PDF”,設置路徑、重命名后加以保存。
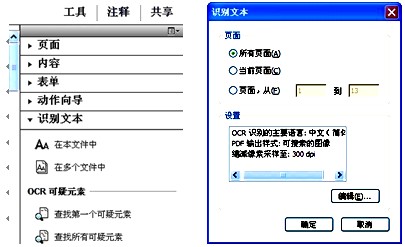
圖5 工具窗格—識別文本 圖6 “識別文本”對話框
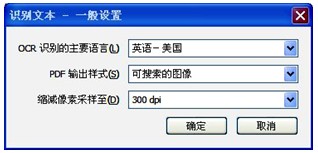
圖7 “識別文本-一般設置”對話框
 |











 恭喜你,發表成功!
恭喜你,發表成功!

 !
!






















