手机看新闻
手机看新闻 分享到人人
分享到人人摘要:图书审核、新闻评论和社区论坛等系统都依赖于关键字过滤。高效、准确的关键词匹配算法能提升这些系统的性能,提高审核人员的效率。本文提出了一种网页敏感关键词匹配的技术,通过对待检测文本预处理,减少敏感词库的负担,采用Trie存储检索敏感词,最大限度地减少无谓的字符串比较,最后通过管理人员的反馈信息及时更新敏感词库使得过滤更加高效。
关键词:信息过滤;文本预处理;Trie;相关反馈
Abstract:Keyword filtering is relied on in many fields such as books review system, news commentary system, BBS, etc. The performance of these systems and the efficiency of reviewers could be improved with efficient and accurate keyword matching algorithm. This paper proposes a webpage sensitive keyword matching technique which could reduce the burden of the sensitive words library through preprocess the text to be detected, minimize meaningless string comparisons by storing sensitive keywords for retrieval with Trie and improve the efficiency of filtering by updating the sensitive words library in time on the basis of feedback information from the administrative staff.
Keywords: Information Filtering, Text Preprocessing, Tire, Relevance Feedback
随着互联网的发展,人们享受网络技术带来的美好生活,同时也使某些非法分子通过网络传送非法信息。随着网络技术的发展和应用,网上色情、暴力、反动等不良信息时有传播,而且有泛滥的趋势。因此,网络信息内容安全值得大家去关注和研究。互联网发展到今天,已经得到很大的普及和应用。目前已经成为一个全球性、开放性、互动性的综合性平台。它容纳了各类型的原始信息,提供了各类型的服务,比如信息获取、网上购物、即时性交流等,给人们工作、生活带来很大的便利。可以说它深入人们的方方面面,是人类信息化技术的一次革命。2011年底,世界网民数量突破21亿,另据中国互联网络信息中心(CNNIC)统计,截止2011年6月中国网民己达4.85亿,成为世界网民最多的国家。网络给我带来便利的同时,也给我们带来许多新的社会问题。由于存在着巨大的经济利益以及世界各个地区与国家、民族之间存在着政治、宗教等矛盾,使得非法人士挺而走险,利用网络开放性的特点,在网上散布各种反动、暴力、色情、虚假广告等不良信息,严重腐烛人们的身心健康,煽动不明真相的人聚众闹事,引起民族之间的强烈仇恨等,给经济社会稳定发展与人们安居乐业带来及其严重的影响。
网络过滤技术就是在这个背景下产生的。目前网页过滤方法主要有关键字过滤、神经元算法、概率统计等技术。据统计网络中70%内容是以文本形式存在,所以对网络文本的过滤是现在过滤技术研究的主要方向。由于关键词过滤相对于别的语义过滤实现简单,过滤速度快等特点,目前己成为绝大多数过滤系统采用的主要方法。比如企业搜索产商Autonomy为我国政府网络信息监测部门量身定做的互联网网页关键字监控分析系统、美国的TDT(Topic Detection and Tracking,话题识别与跟踪)系统、IBM Almaden研究中心开发的WebFountain系统等,这些系统均是以关键字过滤技术为基础,并含有网页信息收等集、海量信息检索和语言检索等功能。关键字过滤和其他过滤算法相比虽然有其自身的缺点,但是建立在一定良好分词基础上,通过合理的特征词优化和关键词算法,在不影响处理速度和空间开销的前提下,同样可以达到理想的过滤效果。
针对网页文本内容的敏感关键词检测技术能够及时有效检测与发现网页中出现的不良文本信息,使网站监控与管理人员及时采取措施进行敏感词的过滤,以防止网页不良信息的蔓延和给社会和人们带来重大损失。
敏感信息监测与过滤技术是网络舆情管理的重要技术,最早起源于图书馆中的应用,1958年Luhn以图书馆检索工作为基础,提出了“商业智能机器”的设想,这个设想最后成了信息过滤的雏形。“商业智能机器”首先它按照用户不同需求的建立相应的查询模型,然后根据这个模型,通过精确的匹配,提取出不同模型相对应的文本集。用户的需求模型并不是固定的,它会根据用户的查询来更新和完善,这个过程虽然简单,但是它涉及了信息过滤的每一个过程,也成为后来信息过滤的开端。然而这个信息更新与维护是靠人工来维护的。1969年,随着电子文本的出现和普及,以及当时出现的文本匹配算法,选择信息分发系统(SDI,Selective Dissemination of Information)开始收到人们的重视。“信息过滤”这个概念是在1982年Demzing提出的,他是在邮件系统中设计了“内容过滤器”,并通过“内容过滤器”来识别紧急邮件和一般邮件,以此来实现对信息内容进行有效性控制。1987年,Malone等人对信息过滤提了出三种信息选择模式,即认知、经济、社会。随着信息过滤技术越来越多的受到重视,1989年,由美国DARPA资助的“Message Understanding Conference”将自然语言处理技术引入文本过滤研究方面进行了积极的探索。它的主要工作是引入了统计学原理,在过滤处理自然语言之前,应用统计技术对信息进行预处理,把这个文本预处理过程叫做“文本检测”。之后Belkin和Croft对用户要求在信息过滤系统流程中的作用做了详细分析,并提出了 “用户角色”这个概念(包括用户兴趣及兴趣表示)。至此,开始出现了用户模板的雏形,为以后文本过滤模型的研究和实现起了指引作用。进入90年代,信息过滤技术得到了很大发展,研究方向也更加具体化,主要出现了以下几个方向:信息过滤、信息检索、分类器及语词抽取等。为了有利于信息过滤的发展,1992 年,美国计算机学家 Nicholas、J.Blkin 和 w.Bmce Croft 在著名的 Communications of the ACM发表的一篇文章中,对文本信息过滤这一名词进行了明确定义,以此来区分其他领域的研究。至此,信息过滤技术已经正式成为一门独立的研究内容,在今后的发展过程中将不断完善。
现阶段,敏感词检测与过滤技术受到了各国的高度重视,在国家的推动下,以敏感信息检测与过滤为目标的应用系统大量出现。Stanford大学的Take.Yen和Hector Garcia-Mina开发了基于内容的过滤系统SIFT(Stanford Information Filtering Tool),这个系统,每个用户可以独立建立自己词汇库,并使用向量空间模型和关键字匹配来实现用户需求与网络信息之间的匹配。美国国家安全局为了更好对恐怖活动、军事威胁等活动进行监控建设了 “Echelon”通信监视网络,它通过卫星接收站和间谋卫星,拦截大量电话、传真和电子邮件等个人信息,Echelon也是一个基于敏感关键字检索来获取通信电子通信系统。英国政府也成立了专门收集情报机构“英国政府技术援助中心”,这个监控中心能够截获和收集所用进出英国的所有互联网信息。
在国内,随着敏感信息检测技术的逐渐成熟,一些科研机构、高等院校和公司通过系统化的技术整合研究,也推出了大量的原型系统和商业产品。如中科天巩公司依托中国科学院计算技术研究所设计开发的天机网络网页关键字监测系统,经过十余年的深入研究,其产品现已推出3.0以上版本。北京交通大学2009年1月成立了国内首个网络网页关键字安全研究机构网络网页关键字安全研究中心,现在正全力推进网络网页关键字产生、传播和导控等方向性研究和自主网络舆论安全关键技术的研发。北京理工大学网络与分布式计算实验室研发了网络网页关键字分析与预警平台。北京拓尔思(TRS)信息技术股份有限公司研制的TRS网络网页关键字监测系统,系统包括了热点发现和追踪、敏感信息监控和预警、辅助决策支持、全方位信息搜索等功能。北大方正技术研究院设计开发了方正智思网页关键字预警辅助决策支持系统,针对离线的网页数据进行网页关键字自动分析和预报,分析规划网页关键字监控内容,形成了一个具有生命特征的周期往复的社情民意反馈系统。南京大学网络传播中心的网络网页关键字监测与分析实验室与谷尼国际软件(北京)有限公司共同建立了网页关键字研究基地,有关Goonie网页关键字监测分析系统也正在国家性课题――“网络舆论引导能力建设研究”中发挥着重要作用。此外,还有上海交通大学信息安全工程学院的网络媒体内容监管系统,也取得了不小进展。
字典树,即Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它具有3个基本性质:
(1)根节点不包含字符,除根节点外的每一个节点都只包含一个字符;
(2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
(3)每个节点的所有子节点包含的字符都不相同。
例如,假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的字典树就是如下图2.3所示:

图2.3 字典树结构
如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在。那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。这样一来我们查询和插入可以一起完成。
本质上,Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。从上图中可以看出:字典树的每条边对应一个字母。每个节点对应一项前缀,叶节点对应最长前缀,即单词本身。单词abcd与单词abd有共同的前缀“ab”, 因此他们共享左边的一条分支,root->a->b。并且字典树的查询操纵非常简单。比如要查找abd,顺着路径root -> a -> b->d就找到了。
搭建Trie的基本算法也很简单,即逐一把每个单词的每个字母插入Trie树。插入前先看前缀是否存在。如果存在,就共享,否则创建对应的节点和边。
在敏感词中加入特殊符号,是目前非法网页来逃避过滤的主要方式,例如上面提到的“法<htl>轮</htl/>功”,识别此类不良信息,首先要过滤掉其中的特殊符号,使其还原文本的自然组合。而在中文的书面用法通常是依靠逗号、句号等断句符号进行断句,而且一些中文分词算法也是以断句符号进行分词处理的。从文中过滤诸如“%”、“&”、等特殊符号,用传统算法直接识别很困难,我们通过建立正则表达式并结合特殊符号对照表的方式进行过滤,使被隔开的歧义敏感词恢复成自然组合状态。
在不良信息中,某些敏感词中的字往往被拼音所代替,对于这种情况,我们基本思想是,首先在训练阶段对敏感词的拼音进行收集,并建立词与拼音的对照表存入数据字典,当发现待检测文本中含有拼音的时候,通过匹配算法,从字典查找与之匹配的字词,来恢复敏感词的自然组合状态。由于汉语中字和词(字是汉语结构的最小单位,词是汉语语义表达的最小单位)的区别,我们从两方面来考虑。1、单字被拼音代替的情况,首先判断被代替字与其相邻字的成词可能性,然后在字典中查找判断该词是否为敏感词,建立拼音与字词对照表,恢复其自然组合状态;2、多字被拼音代替的情况,利用字典直接建立拼音与可能代替的词对照表,判断其是否为敏感词,如果是,则将敏感词恢复成自然组合状态。
对于某些字母与数字组合的敏感字,例如“法LOng功”,用数字“0”来代替“Long”中的“0”,由于两者形式非常相似,很容易让人们理解其含义。这种情况首先建立敏感词拼音表,然后通过自定义的正则表达式,对常见敏感信息的所有拼音逐一匹配。
对于敏感字中还有偏旁部首或其他非单字的情况,我们还是需要借助字典来识别需要借助字典进行匹配和识别,识别过程描述如下:
(1)对待查文本进行扫描,查找文中是否存在偏旁或部首,如果存在,则判断其右邻的字是否同样为偏旁或部首。
(2)首先确定该偏旁部首结合其相邻字的构成词能力,如果字典中确实存在与之对应的子结构,则建立词表并统计该字在文中出现的次数;如果没有找到,则转到步骤( 3)。
(3)如果在字典中没有找到相对应的字,则认为敏感词中不含有被拆分的字,转到步骤(1),继续查找该偏旁部首后面可能出现的偏旁字。

图1 待检测文本预处理过程
网页敏感关键词检测系统主要完成对待检测网页的敏感关键词检测,并对检测出的敏感关键词,标出其在源文件中的位置,将检测结果与检测时间等信息写入敏感关键词检测结果表中。系统在敏感词检测期间需要驻留内存,通过加载敏感关键词知识库来做敏感关键词的检测。网页敏感关键词检测系统的流程图如下图2.1所示。
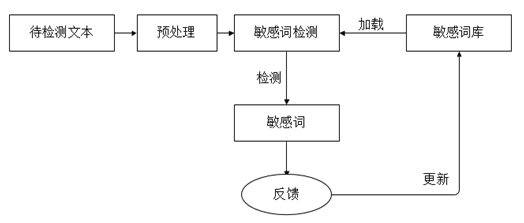
图2 网页敏感关键词检测系统流程图
上图为网页敏感关键词检测系统的流程图,其敏感词检测具体步骤如下:
1、创建敏感关键词库。
2、敏感关键词检测系统启动,加载敏感关键词库到内存。其中敏感关键词按照Tire字典树形式存储。
3、系统通过目录文件读写子模块读取待检测文本。
4、待检测文本预处理。
5、系统通过扫描指针读取待检测文本中每个字符,使用哈希散列函数将每个字符映射到字典树中进行敏感关键词检测;
6、如果发现敏感关键词,则标记其位置信息,获取敏感关键词的上下文作为该敏感关键词的摘要内容,获取系统当前时间,然后调用关系型数据库读写子模块将其写入敏感关键词检测结果表中。
7、如果没有发现敏感关键词,则扫描指针调下下一个字符;
8、重复步骤(5),(6),直到扫描指针指向文本结尾。
9、管理员根据匹配到的上下文进行判断,判断其是否为敏感词,给系统做出相关反馈,或者在这些词语中得到提示,添加新的敏感词库,及时更新关键词库。
本文首先简单概述了网页敏感关键词检测技术在当前网络信息多元化与复杂化环境下的研究背景与重大意义。接着说明了该技术在国内外的研究现状与应用的实际场景。然后详细介绍了网页敏感关键词检测系统的运行流程与敏感关键词检测过程。重点说明了待检测文本的预处理,以及敏感关键词库在内存中的字典树存储形式。对网页敏感关键词检测系统做了具体的设计与实现,该系统可以准确的检测出待检测文本中的敏感关键词,敏感词位置及上下文摘要等具体信息,并在实际的页面中将检测出的敏感关键词进行了标注,管理员可以通过检测出的敏感词进行判定,并反馈给系统,及时更新词库。
[1] CCNIC, 《第29次中国互联网络发展状况调查统计报告》,2012
[2] Wang X, Li H, Jia Y, et al. Proceedings of the 2012 International Conference on Information Technology and Software Engineering[M]. Springer Berlin Heidelberg, 2013:991-1000.
[3] 王博文. 通用类trie树及自动生成[J]. 计算机应用, 2000, (12):74-75.
[4] 王博文, 苏国辉. 用于汉字拼音输入的类trie树及其改进[J]. 小型微型计算机系统, 2002, (6):759-761.
[5] Tang Pei-li, Wang Shu-ming, Hu Ming. Algorithm of Thematic Words Extraction from Chinese Texts Based on Semantic [J]. Journal of Changchun Post and Telecommunication Institute, 2005-05.
[6] Luo Zhun-chen, Wang Ting. Research on the Chinese Keyword Extraction Algorithm Based on Separate Models [J]. Journal of Chinese Information Processing, 2009-01.
[7] 白立军, 张银福. 基于网络安全的字符串匹配算法研究[A]. 第二届全国信息检索与内容安全学术会议(NCIRCS-2005)论文集[C], 2005年
[8] 张文鹏, 王兴. 基于中文关键词提取的预案智能匹配方案[J]. 科学技术与工程, 2012, (21).












 恭喜你,发表成功!
恭喜你,发表成功!

 !
!