手机看新闻
手机看新闻 分享到人人
分享到人人摘 要: 并发程序中的数据竞争问题很难被检测和修复.以往的研究大多针对用户层的数据竞争检测并在此问题上取得了重大的进展,但在操作系统内核层面的数据竞争问题却几乎没有涉及.内核代码使用的同步机制远比用户层应用程序中复杂,如不同种类的锁,软硬件中断,大量的信号量原语以及各种底层的共享资源等.这些差别使得原有的用户层检测方法很难被应用到内核环境中.本文给出一个可有效检测Linux操作系统内核数据竞争问题的工具,基于当前通用处理器中现有的硬件结构调试寄存器,使用动态检测方法在内核程序运行过程中捕获数据竞争.初步的实验结果显示,本工具可有效地检测到内核中的数据竞争实例.
关键词: 数据竞争检测;Linux内核;同步机制;调试寄存器;采样
1 引言
并行程序设计对保持未来计算性能的持续提升有非常重要的影响,但其使用过程中会遇到很多复杂的问题,数据竞争就是其中之一.当两个没有被同步机制有效约束的线程同时访问一处共享内存空间,其中至少有一个写操作时,就构成了数据竞争.它们不仅会影响程序运行结果导致错误的输出,还会造成严重伤害事故和大量经济损失.如Therac-25医疗事故[1],北美电网瘫痪事件[2]和Facebook IPO故障[3]等.随着多线程程序的广泛应用,这类事件还会继续发生并带来更多难以预料的后果.
现有的很多种针对用户级程序的动态数据竞争检测工具[4~6]实质上都是通过动态地监控并行程序的多个线程在并发执行过程中发生的内存访问操作和使用的同步机制来工作的.由于数据竞争在运行时显现的几率很低,这些工具会用各种算法去推断可能发生冲突的并发执行访存操作,它们的不同之处一般体现在推断的方法上:使用happens-before[4]关系来判定同步操作的顺序,或者使用lock-set[5]来计算它们发生的时间前后,或者同时使用两种方法[6].
Happens-before方法的基本原理是通过推断多线程程序中可能的指令发生顺序来报告潜在的竞争性线程交错顺序.由对线程内事件的发生顺序和线程间同步原语的监控而推断出的信息称为指令间的happens-before关系.若两个冲突的指令间不存在happens-before关系,就可以推断它们构成了一个数据竞争.尽管happens-before方法不会产生误报,但大量的记录和推断工作仍然是非常复杂和耗时的.
当被检测的并行程序在编写时使用了高度一致性的标准锁机制的情况下,lock-set方法才能够较好地发挥其优势.它的主体思想是在每个线程访问共享数据时检查它所拥有的锁的集合,计算该处内存地址所有锁集合的交集.若该交集不为空,检测工具则会报告此共享数据未被保护且有可能发生数据竞争.此方法是针对共享内存地址进行可能的冲突检测而不是针对数据竞争产生的根本原因和导致数据竞争的错误指令,这使得它对在并行程序故障检测的辅助功能上变得十分局限.此外,对于锁机制的高要求也不适用于那些使用了多种同步机制的并发系统.
将以上方法应用于内核程序的数据竞争检测工作中会遇到很多问题.首先,内核模式的代码运行于更底层的并发抽象,没有用户模式代码所依赖的由内核提供的线程和同步机制的简洁抽象.在内核中,同一个线程的上下文执行的可能是一段用户模式进程的代码,或一个设备中断服务例行程序,也可能是一个延期的过程调用(DPC, deferred procedure call).通过理解内核中复杂的同步机制原语的语义来推断happens-before关系或计算lock-set都是相当繁重的工作.例如,在关于锁的持有者与硬件中断的同步协调问题上,内核模式中就有数十种不同语义的锁机制支持这项功能.内核模块导入同步机制原语的定制实现也是非常常见的.
其次,面向硬件的内核模块需要与并发改写自身和内存状态的硬件设备保持同步.这使得设计一个能够发现这些其他手段难以发现的硬件与内核之间的数据竞争的检测工具显得尤为重要.
最后,现有的动态数据竞争检测工具普遍会带来较高的运行时开销,主要是由在运行时监控和处理所有的内存操作和同步操作产生的.在构建数据竞争检测工具的过程中很大一部份工作都致力于降低运行时开销和相关的内存和日志管理的问题上[7].在内核复杂的编程环境中复制这些工作即使可能,也是一项非常耗时费力的工作.此外,现有工具所使用的侵略性插装技术也很难应用于底层的内核代码.
DataCollider[8]是能够较好地解决以上问题的一个在内核模块中动态检测数据竞争的轻量级工具.它能够绕开传统的程序分析方法,利用现有硬件结构中的调试寄存器对复杂的内核代码进行有效的数据竞争检测,并通过采样少量的访存操作来降低系统的运行时开销.但由于该工具基于闭源Windows操作系统的实现给它的实际应用带来了极大的不便,本文基于它的原理给出了DRDDR(Data Race Detection using Debug Register)内核数据竞争检测工具,将其实现于基于x86架构的64位Linux内核中,构建了人工测试用例和两个真实系统中的数据竞争实例以验证DRDDR的有效性,最终将其部署于内核的文件系统中运行并检测到了一些新的数据竞争问题.
本文其余部分内容安排如下.第2节给出了DRDDR概述并在第3节介绍它的实现细节.第4节的内容是关于DRDDR的实验及评估.第5节将对与本文工作相关的工具进行分析和比较.第6节是本文的总结和未来工作.
2 DRDDR概述
DRDDR利用当前计算机硬件系统结构中的代码断点和数据断点,通过采样程序中的少部分访存操作进行数据竞争检测.因此它不会给未被采样的代码区域带来额外的运行时开销,只需设置一个低采样率就可达到以微小开销开展数据竞争检测工作的目的.

DRDDR通过以下方法来克服前文提到的内核数据竞争检测中的几点问题.它所采用的核心算法如图1所示.DRDDR首先通过运行时在随机选取的访存指令上插入代码断点的方法来采样少量内存访问操作.当代码断点被触发,DRDDR会对被采样的访存开一个小的时间窗口,并同时采用两种策略检测与该访存有关的潜在的数据竞争.一种是设置数据断点来捕获其他线程的冲突访问.而为了检测到由硬件设备和处理器通过不同的虚拟地址访问该处内存地址导致的数据竞争,DRDDR还采用了一种“数值比较”的策略,它会在时间窗口前后各读取一次当前内存地址的数据值,如该值发生改变则说明在延迟期间发生了冲突读写,即数据竞争.
本节以一个手动构建的模拟测试用例为例介绍DRDDR核心算法在内核环境中的实现.如图2所示,RWrace的功能是产生两个内核线程cafe_machine和cafe_taster,并且分别定时对一个共享对象current_cafe进行读写,它的值在每一次循环都会被一个随机数flavour改变.由于整个程序完全没有进行任何同步,这两个线程的任意两次读写,根据定义,都是一次数据竞争.这个内核模块是并行程序中最简单的数据竞争的形式之一.
由图可见语句①与语句②是数据竞争发生过程中的关键冲突部分.在此例中,我们首先选择一个关键语句,以语句①为例,通过插入代码断点的方法使程序停在此处.然后使用反汇编器得到该语句所访问的变量即current_cafe在内存中的位置,在此设置数据断点并等待一段时间,若期间线程2的语句②正在执行,就会产生对current_cafe的读操作继而触发数据断点,DRDDR就会报告此处为数据竞争.

DRDDR算法有两个特征使其适用于内核中的数据竞争检测.第一点也是最重要的一点,它很易于实现.除了一些实现细节(第3节)以外,它的全部算法都在图1中展示出来了.此外,它与内核使用的同步机制协议和硬件结构完全无关,无需考虑其中同步原语的复杂语义是DRDDR的一个非常受欢迎的设计点.
当DRDDR通过数据断点机制发现一个数据竞争的情况下,两个问题线程在即将执行冲突访存操作时被即时捕获.由于DRDDR可以收集到很多有用的调试信息,诸如沿冲突线程上下文信息的堆栈踪迹等,这大大简化了对它给出的错误报告的分析工作,而且不会给未被采样的或未发生竞争的访存操作带来额外开销.
并非所有的数据竞争都是有害的.有些情况下它们不会影响程序的输出,如对日志/调试变量的更新;或者以一个程序员可以接受的方式影响程序的输出,如对一个低保真度计数器的冲突更新等.这类数据竞争被称为良性竞争.在DRDDR的实验测试结果中就存在这类问题,我们会在第4节详细介绍.
3 DRDDR实现
本章介绍了DRDDR的算法在基于x86系统架构的Linux操作系统内核中的实现细节.其中主要使用了硬件结构中现有的代码断点和数据断点机制.它们同样可以应用于其他的体系结构或扩展到用户级别应用程序,这方面内容本文暂不涉及.
图3展示了DRDDR的核心思路.它首先通过采样的方法,详见3.1,在内核程序大量的内存访问操作中选取少部分进入下一阶段的分析.然后使用3.2中的反汇编器对这些指令进行反汇编,找出其所访问的内存数据地址.对每一个内存中被采样并定位的共享数据,DRDDR使用冲突检测机制,详见3.3,去查找与该处有关的潜在数据竞争问题.
![]()
3.1 采样
为数据竞争检测工具设计一个好的采样算法有很多挑战.首先,与数据竞争有关的两个访存操作都要被采样到.如果单独进行采样访存操作会大大降低检测到数据竞争问题的概率.DRDDR通过只采样其中一个访存而利用数据断点去捕获另一个访存的方法绕开了这个棘手的问题.这使得它能够以较低的采样率获得较好的工作效率.
其次,由于数据竞争在并行程序中发生的概率较低,绝大多数运行中的指令都不会出现问题.这就需要采样算法能够将少部分容易出现问题的访存指令从大量不易出现问题的指令中捡选出来.这里最关键的因素是如果程序中某处是有问题的如访问共享数据时错误地使用了同步机制,那么该问题程序的每一次动态执行都有可能导致数据竞争.因此,DRDDR选择在内核代码中进行静态采样而不是在运行时指令中动态地进行.静态采样方法为那些很少被执行到的指令提供了公平的机会,使得它们也能被检测到是否有可疑的数据竞争问题.
DRDDR运用一个简单的静态分析方法来从采样集合中排除那些只访问了线程本地堆栈地址的指令.同样地,它还会排除一些访问了标记为“volatile”的内存地址或使用了硬件同步原语的指令.这能够帮助DRDDR避免报告出关于同步功能变量的数据竞争,以免给用户带来不必要的麻烦.
DRDDR通过插入代码断点的方法来从采样集中选取需要进行检测的内存地址.起初断点被设置在从采样集合中随机选取的少量内存地址上.如果一个断点被触发,DRDDR就会对该处的内存访问操作进行冲突检测,然后再选择另外一个从采样集合中随机选取的程序地址设置断点.
这个算法一直是从采样集合中随机地选取程序地址而不考虑那些地址的实际执行频率高低.经过一段时间的运行,设置断点的位置就可能选择在一些很少被执行到的程序地址上,提高了这些地方获得数据竞争检测机会的可能性.
3.2 反汇编
给出一个并行程序的二进制文件,DRDDR首先用反汇编器将其反汇编并生成一个由所有访问了内存的程序地址组成的采样集合.它会并发地向程序的二进制文件发送调试符号来完成反汇编.这项需求在未来可通过使用更加复杂的反汇编器来提高工作效率.
关于本文中反汇编器的实现, DRDDR移植了KVM(Kernel Virtual Machine)中一部分相应的功能.选择KVM主要考虑到它是一个功能简洁且可移植性强的开源工具,可以帮助我们在较短的时间完成工具中一部分比较复杂的功能. KVM 中的反汇编器并不是严格意义上的反汇编器――由于 KVM是一个虚拟机,它的反汇编器被设计成仅仅用来解释执行那些不能完全被硬件虚拟执行的指令.所以反汇编器只支持 x86 指令集的一个子集.而DRDDR的需求是反汇编所有的访存指令,因此本文自行实现了实验中遇到的绝大多数 KVM 反汇编器里没有处理的访存指令的反汇编功能.
此外,DRDDR还实现了一个“内核态-用户态”交互模块用以为用户提供实时调试信息.该模块主要利用用户模式的调试文件系统(debugfs)通过文件的形式向DRDDR发送可疑的内存地址列表.
3.3 检测策略
如图4所示,在通过采样算法选取了少部分程序地址作为数据竞争检测对象后,DRDDR会先暂停该内存数据地址的当前线程1,等候看是否有其他线程在此期间对该处内存地址进行冲突访问.它使用了两种策略:数据断点和数值比较,作为对彼此缺陷的补充.数据断点策略能够在有其他线程2在等候期间访问此处时产生调试中断报告冲突.而数值比较策略则在等候时间窗口前后记录该处内存数据的值并进行比较以捕获数据断点策略可能遗漏的数据竞争问题.

3.3.1 数据断点
现有的硬件体系结构提供了在处理器读取或写入某个内存地址时进行捕获的功能,这对于有效地支持在调试器中设置数据断点起到非常关键的作用.DRDDR利用了x86硬件提供的4个数据断点寄存器对可能与被采样的访存发生冲突的其他访存操作进行了有效的监控.
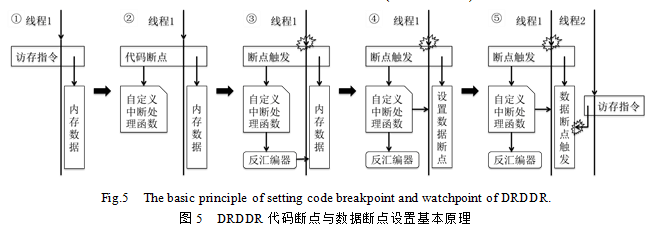
DRDDR通过以下步骤使用由调试寄存器提供的代码断点和数据断点功能,如图5所示.
1) 对于待检测的访存指令,DRDDR会将该指令汇编代码的第一条语句替换成INT3中断即代码断点指令,并同时将INT3中断处理函数换成本工具自定义的处理函数以备对该处进行后续操作使用(图5①-图5②);
2) 当程序运行到待检测指令的INT3中断语句,代码断点被触发,自定义中断处理函数被调用,它会利用上一节中介绍的反汇编器对发生中断的指令进行反汇编,以找到该指令所访问的内存中共享数据的地址,并在此地址上添加INT1中断即数据断点对其进行监控(图5②-图5③-图5④);
3) 若有其他线程在监控期间访问了此地址的共享数据,数据断点将被触发,DRDDR会认为这个线程的访存指令与原来线程发生了数据竞争并对其进行后续的处理和验证(图5④-图5⑤).
若当前访存是写操作,DRDDR会令处理器处于等待捕获对该地址的读操作或写操作的状态;若是个读操作,就只令处理器等待捕获对该地址的写操作即可,因为对同一地址的两个读操作不会发生数据竞争冲突.如果没有检测到冲突的操作,DRDDR就会在清除了数据断点寄存器之后恢复当前线程的执行.
每个处理器都有一个单独的数据断点寄存器,DRDDR利用一种处理器内部中断来原子性地更新所有处理器上的断点,这也使那些要在不同的访存操作中并发采样的多个线程得到了有效地同步.一个x86指令可能访问到不同长度的内存地址,如8位,16位,32位,DRDDR能够分别为他们设置适合的断点,对于长度大于32位的访存指令,DRDDR可以同时使用至多4个寄存器来设置断点.如果调试寄存器的功能还不足以检测到数据竞争,数值比较策略还可以进行补充.当数据断点被触发,DRDDR就成功地检测到了一个数据竞争.更重要的是,它是在发生现场捕获到的――两个线程正好处在对同一处内存地址进行并发访问的状态中.
x86中对数据断点的支持有一个缺点,当分页功能开启时,系统会基于虚拟地址进行断点比较且没有其他可变机制.两个对同一虚拟地址但不同物理地址的访存操作会使DRDDR发生混淆.如果访问用户层地址空间的内核线程是执行在不同进程的上下文中,它们之间不会发生冲突.若被采样的访存存在于用户地址空间,DRDDR就不会使用断点策略而是默认选择数值比较策略进行检测.
如果处理器用不同的虚拟地址映射到相同的物理地址,数据断点将会漏掉该处的数据竞争.它也无法检测到由硬件设备直接访问内存导致的数据竞争.数值比较策略则能够弥补这些问题.
3.3.2 数值比较
数值比较策略的主要依据很简单:如果一个冲突的写操作改变了某内存地址处数据的值,DRDDR可以通过重复读取该处内存地址来核实数值是否被改变.这个方法有个明显的缺点是它不能检测到读操作与写操作冲突的情况,同样,它也不能检测最后一次写入与初始值相同的数据的多重冲突写操作.尽管如此,本策略在实际工作中还是非常有效的.
然而,数值比较策略只能将发生数据竞争的两个线程其中之一当场抓住.这会给后续的查错工作带来一些困难,因为我们不知道是哪个线程或设备在此期间访问了被监控的内存地址.这也是使用数据断点策略的主要动机和初衷.
4 实验与评估
DRDDR的性能评估测试用例主要有两种来源:手动构造的数据竞争模拟测试用例和真实内核环境中已被发现的数据竞争实例.前者在本文的第2部分已有介绍,本节主要对后者的内部机制和重现细节进行分析.
4.1 测试用例
本文通过筛查Linux系统内核使用的代码错误管理工具Kernel Bugzilla[9]中的所有与数据竞争有关的错误来选择典型的,被深入讨论并完美解决的错误实例来对DRDDR的正确性进行验证.实验表明,DRDDR可以准确地检测到这些真实的数据竞争错误.这里以 Linux 内核中出现过并被修复的两个数据竞争为例进行详细介绍. 其中之一是出现在 eCryptfs文件系统的数据竞争错误.另一个故障发现于ext2文件系统的源代码中.
4.1.1 eCryptfs
eCryptfs内核数据竞争是一个顺序违例故障.它出现在Linux内核版本3.0-rc1中,并通过补丁[10]得到修正.
该故障存在于eCryptfs文件系统中,图6给出了竞争双方线程中的关键语句.虚拟文件系统为每一个文件在内存中维护一个唯一的inode节点,当文件第一次被使用时,虚拟文件系统会创建一个dentry文件(包含文件路径)然后在eCryptfs中查找它.如果找到,eCryptfs就新建一个inode节点,将它初始化并赋给dentry;这个inode在创建之初是被锁住的,eCryptfs在初始化后需要先将它解锁,然而在这一版本的Linux内核中,eCryptfs在初始化节点的长度之前就将它解锁了,导致其他冲突的访问有机可乘并引发数据竞争错误.

触发此错误需要带有一个文件的新挂载的eCryptfs文件系统,这是为了保证内核中不存在该文件的inode节点.一个进程打开此文件的过程中会先进行一次查询,此时另一进程也打开它并写入一些内容以改变文件大小.如恰好后者的操作发生在查询进程的解锁和初始化文件大小之前,那么文件的长度保持不变,而写入进程所记录的内容也将全部丢失. 通过在对i_size_write的访存指令处加入断点,DRDDR可成功检测到此数据竞争.
4.1.2 ext2
ext2内核数据竞争是一个原子性违例故障.它出现在Linux内核版本2.6.38-rc8中,并通过补丁[11]得到修正.
这个数据竞争是由一些操纵inode节点的硬链接计数冗余代码错误地使用锁造成的, 图7给出了竞争双方的关键语句.命令ln和link以及系统调用link()和linkat()可被用来创建硬链接.一个文件的内容用inode结构来表示,它有个i_nlink成员来记录指向它的链接数目,可通过“ls -l”命令来查询.在为ext2进行重命名的ext2_rename()函数中,程序将模拟链接从旧文件转移到新文件,再将清除旧文件的链接.这样在增加新链接时它就会给新inode的i_nlink加1给旧inode的i_nlink减1.然而ext2_rename()函数和调用它的函数都没有先取得旧文件的inode的锁就进行了操作,这就导致ext2_rename()函数在没有保护的情况下改写了i_nlink,与ext2_link()函数和ext2_unlink()函数形成了数据竞争.通过在对i_nlink的访存指令处加入断点,DRDDR可成功检测到此数据竞争.

4.2 实验结果
本文选择了两套用户态的测试程序,一是LTP(Linux Testing Project),使用了其中的如fsstress和racer等测试工具;另一套是 UnixBench,通过对内核里的文件系统代码施加大量压力来增加 DRDDR 查到数据竞争的可能性.在重现ext2文件系统的数据竞争以及发现新的良性数据竞争的实验中,这些用户态程序都起到了重要的作用.
DRDDR实现了一套简单的程序,用正则表达式匹配等方法找出内核中所有用户指定函数里的所有访存指令,并排除了对栈内对象的访问操作,因为栈内对象既很难成为多线程程序的共享数据,也会由于进入中断上下文时更换栈地址而被很好地隔离.在测试过程中,主要把重点放在内核文件系统部分的代码中,分析程序找出的访存地址大约有40000多个(依内核版本和编译选项而不同).
我们使用DRDDR检查Linux内核,最多检查了5000条访存指令.在实验过程中DRDDR发现了一些良性的数据竞争.下面以其中两个为例进行简要介绍.其一是在内核程序函数core_sys_select()中,有一句判断当前线程是否有等待处理的信号的指令.在执行期间随时可能会发生定时器中断,中断处理函数会在当前线程时间片耗尽的情况下把当前线程设置为需要重新调度.这两个标志位属于同一个变量,因此,若仅从读-写竞争的角度考虑,它们确实构成一个数据竞争.但实际这个读-写操作涉及的是同一个变量的不同位,又由于这个写操作是带总线锁的,而且中断部分的代码虽然可以从非中断代码的任意位置进入,两部分代码却不可能同时执行.这些因素都可表明此数据竞争是良性的.
另一个良性数据竞争出现在Linux文件系统处理管道读写操作的函数pipe_read()中.我们首先从文件系统中函数名包含“pipe”字样的函数中选出425个访存指令,在其中设置了300个代码断点,然后运行Unixbench中的一个测试并发管道操作的基准测试程序进行数据竞争检测.在pipe_read()函数中,有一个访存操作读取了当前任务的标志位以检查是否有信号被挂起.当任务停在这条指令上时,它会被DRDDR强制进行一轮短时间的等待.在等待期间就有一个硬件定时器中断发生并改写了挂起信号的标志位,形成数据竞争.该竞争被判定为良性的主要原因是它是读写操作冲突并且两个指令访问的是一个字节的不同位.
在此之前,DRDDR运行在Linux文件系统上还得到了另外两个良性数据竞争.但是它们与上述两例在原理上类似,只是涉及到的具体代码不同,这里便不再赘述.
5 相关工作
由于DRDDR是一个动态检测工具,本节只对与其同类的相关工作进行简单介绍和比较.动态数据竞争检测的方法主要有两种:happens-before[12~14]和lock-set[5],它们的工作原理在引言部分已详细介绍.
与本文工作最接近的相关工作是DataCollider[8]. 它利用现有硬件实现了一个有效的动态数据竞争检测技术. 在采样的内存访问操作中, 通过暂停访存线程并使用断点来监控那些在此期间访问了该内存地址且没有同步机制控制的其他线程的访存操作来检测潜在的数据竞争.它能够保持较低的开销但却因采样率较低而难以保证足够的覆盖率.目前为止还不清楚DataCollider能否随着核数的增加而进行扩展.除此以外,这项工作最重要的问题是基于不开源的Windows系统进行的源代码不公开的检测工具研究, 这无论对于真正需要该工具的用户的使用还是对进一步的科学研究都带来了极大的不便. 本文的工作正是从这一点出发, 首先在检测对象的选择上以科学研究领域最广泛使用的Linux系统为基础, 其次在各项功能的实现上均使用开源工具, 最后将所研发的工具无偿贡献给开源社区, 既满足了有这方面需求的用户的使用, 又给相关领域的学者在此方向上继续进行更深层次的研究带来了极大的便利.
还有一些其他的利用硬件辅助进行数据竞争检测的工具例如RACEZ[15],HARD[16],和RaceTM[17].它们分别在算法设计中使用了硬件系统中的性能控制单元(Performance Monitor Unit, PMU),布隆过滤器(Bloom Filter)以及硬件事务内存(Hardware Transactional Memory, HTM)等结构,其中硬件事务内存还只是利用模拟器进行的实验.得益于硬件良好的性能,这些工具都具备良好的效率和可操作性,但它们仍然无法适用于拥有大量复杂同步机制原语的内核代码环境.
6 结论与未来工作
本文通过利用x86体系结构中现有的硬件结构调试寄存器来辅助进行内核系统中的数据竞争错误检测, 将此方法实现在了科学研究领域最广泛应用的Linux操作系统上, 验证了工具的正确性和有效性并通过对两个真实内核环境中的数据竞争错误实例的分析和实验效果的介绍来进一步阐述了系统原理.
作为未来探索的一个平台,本文工作还有很多有趣的问题可以延伸和拓展.
首先是已报告的数据竞争错误的事后处理.在发现数据竞争之后,除了现有的标准寄存器,栈轨迹(Stack Trace) 以外,应当考虑还有哪些有助于调试的信息.此外,尝试区分有害的数据竞争和良性的数据竞争也是值得考虑的方向之一.本工具查出的若干类似的良性数据竞争也给我们以启示:自动查错工具如何识别相似的错误,是否可以通过合并相似错误的方法,减少人工检验这些检测结果的成本.
其次,对源代码的预分析也是十分重要的环节.当前实现中断点列表是把所有的内存访问的指令提取出来,唯一进行的处理是忽视了用sp和bp寻址的访存,因为它们操作的是栈上的元素,而实际上绝大多数访存指令访问的地址仍然是非共享的数据.因此,加强对源代码的静态分析,也有可能极大地减少这种浪费,提高查错的效率.
最后,考虑到检测工具给程序带来的开销问题,我们还可以在采样机制上对其进行改进.随机取样的方法虽然简单易行,但也有一定的缺陷.它在准确性上的不足会给后续的检测工作带来额外的开销.程序中大多数的程序地址都可能是数据竞争无关的,盲目对每一处访存操作采样会使检查开销增大.如果某个经常被执行的函数中不涉及数据竞争,而随机的采样的方法恰好选择了该处插入断点,就会引入大量不必要的操作,造成资源和时间浪费. 如果我们能够通过程序标记或预分析[18]等方法提前获得关于哪些程序位置更有可能发生数据竞争,就可以在随机取样时优先选择这些位置来提高检测成果的有效性.
References:
[1] Leveson, Nancy G., and Clark S. Turner. "An investigation of the Therac-25 accidents." Computer 26, no. 7 (1993): 18-41.
[2] Poulsen, Kevin. "Software bug contributed to blackout." Security Focus (2004). http://www.securityfocus.com/news/8016
[3] Joab Jackson. "Nasdaq's Facebook glitch came from `race conditions'", 2012. http://www.computerworld.com/s/article/9227350
[4] Lamport, Leslie. "Time, clocks, and the ordering of events in a distributed system." Communications of the ACM 21, no. 7 (1978): 558-565.
[5] Savage, Stefan, Michael Burrows, Greg Nelson, Patrick Sobalvarro, and Thomas Anderson. "Eraser: A dynamic data race detector for multithreaded programs." ACM Transactions on Computer Systems (TOCS) 15, no. 4 (1997): 391-411.
[6] Choi, Jong-Deok, Keunwoo Lee, Alexey Loginov, Robert O'Callahan, Vivek Sarkar, and Manu Sridharan. "Efficient and precise datarace detection for multithreaded object-oriented programs." In ACM SIGPLAN Notices, Conference on Programming language design and implementation, PLDI'02, vol. 37, no. 5, pp. 258-269. ACM, 2002.
[7] Yu, Yuan, Tom Rodeheffer, and Wei Chen. "Racetrack: efficient detection of data race conditions via adaptive tracking." In ACM SIGOPS Operating Systems Review, Symposium on Operating Systems Principles, SOSP'05, vol. 39, no. 5, pp. 221-234. ACM, 2005.
[8] Erickson, John, Madanlal Musuvathi, Sebastian Burckhardt, and Kirk Olynyk. "Effective Data-Race Detection for the Kernel." In Proceedings of the 9th USENIXconference on Operating systems design and implementation, OSDI'10, vol. 10, pp. 1-16. 2010.
[9] Linux Kernel Bugzilla, https://bugzilla.kernel.org
[10] Report and discussion ecryptfs bug in Linux kernel, https://bugzilla.kernel.org/show\_bug.cgi?id=29752
[11] Report and discussion of ext2 bug in Linux kernel, https://bugzilla.kernel.org/show\_bug.cgi?id=36002
[12] Bond, Michael D., Katherine E. Coons, and Kathryn S. McKinley. "PACER: proportional detection of data races." In ACM Sigplan Notices, Programming Languages Design and Implementation, PLDI'10, vol. 45, no. 6, pp. 255-268. ACM, 2010.
[13] Marino, Daniel, Madanlal Musuvathi, and Satish Narayanasamy. "LiteRace: effective sampling for lightweight data-race detection." In ACM Sigplan Notices, Programming Languages Design and Implementation, PLDI'09, vol. 44, no. 6, pp. 134-143. ACM, 2009.
[14] Flanagan, Cormac, and Stephen N. Freund. "FastTrack: efficient and precise dynamic race detection." In ACM Sigplan Notices, Programming Languages Design and Implementation, PLDI'09, vol. 44, no. 6, pp. 121-133. ACM, 2009.
[15] Sheng, Tianwei, Neil Vachharajani, Stephane Eranian, Robert Hundt, Wenguang Chen, and Weimin Zheng. "RACEZ: a lightweight and non-invasive race detection tool for production applications." In Proceedings of the 33rd International Conference on Software Engineering, ICSE'11 pp. 401-410. ACM, 2011.
[16] Zhou, Pin, Radu Teodorescu, and Yuanyuan Zhou. "HARD: Hardware-assisted lockset-based race detection." In High Performance Computer Architecture, 2007. HPCA 2007. IEEE 13th International Symposium on, pp. 121-132. IEEE, 2007.
[17] Gupta, Shantanu, Florin Sultan, Srihari Cadambi, Franjo Ivancic, and Martin Rotteler. "Using hardware transactional memory for data race detection." In Parallel and Distributed Processing, 2009. IPDPS 2009. IEEE International Symposium on, pp. 1-11. IEEE, 2009.
[19] Sheng, Tianwei, "Researches on Key Technologies of Data Races Detection in Concurrent Programs", [Doctoral Dissertation]. Beijing: Tsinghua University, 2010.
[18] 盛田维.并发程序数据竞争检测关键技术研究[博士学位论文].北京:清华大学,2010.












 恭喜你,发表成功!
恭喜你,发表成功!

 !
!