�ֻ�������
�ֻ������� ����������
����������ժ Ҫ����þ�ȷ��IP-to-ASӳ������������������Ա���������ϺͶ��������о���Ա����AS����������������Ҫ�����塣һ�ֻ��IP-to-ASӳ����ķ����ǻ���traceroute·����BGP ��AS·����һ�µļ��裬ͨ�����ƥ��traceroute��BGP·���Ե���������������·�ɱ�����ȡ�ij�ʼ��IP-to-ASӳ������������������ʼ��IP-to-ASӳ��������������ȵ�����������һ����/24ǰ���ȵ���������[1]����һ����IP��ַ���ȵ���������[2]��IP��ַ���ȵ��������������ǰ���ȵ��������������Դ�����·���Ե�ƥ��ȡ�����ǰ���ȵķ�����IP��ַ���ȵķ���������ȱ�㣬���������һ��ϵͳ���Ļ��ڷ������ķ�������������ϵͳ��ȫ��Ͷ����ķ���ǰ���ȷ�����IP��ַ���ȷ������Ե���ȱ�㡣
�ؼ��� ����������ַ��������ӳ�䣻��������
1 ����
IP-to-ASּ��ΪIP (Internet Protocol��������Э��) ��ַ�϶�ʹ�ø�IP��ַ��AS��Autonomous System����������Ҫ�ر�˵�����ǣ�����һ��IP��ַ��˵��ʹ������AS������һ���ǵ�ַע����������������AS�������ǵ�IP-to-ASָ����IP��ַ��AS֮���ʹ���뱻ʹ�ù�ϵ��������IP��ַ��AS֮��ķ����뱻�����ϵ��
��ȷ���϶�IP-to-ASӳ����������������Ա��Ϲ��ϺͶ��������о���Ա����AS����������������Ҫ�����塣���磬traceroute���Ը���Դ��Ŀ����������·�����Ľӿ�IP��ַ������ܹ�֪���ӿ�IP��ַ���ڵ�AS�ţ������ʹ���������Ա�������ȥ������ϡ����⣬����IP-to-ASӳ��������Խ�IP�����traceroute·��ӳ�䵽AS�����traceroute·��������������о���Ա����AS����������Ҫ���壺����Traceroute����AS�����˿��Բ������BGP��Border Gateway Protocol���߽�����Э�飩���ֵ�AS�����ˣ��Ҳ���traceroute����Ȳ���BGP����Ҫ���Ķֻ࣬Ҫһ̨��ͨ�������Ϳ�����Ϊtraceroute���㣬������BGP����Ҫ���ѵĺܶࡣ
Ϊ�õ���ȷ��IP-to-ASӳ�����Ŀǰ���������һ��������·�������������õ�IP��ַ��·������ӳ�䣬Ȼ���ٽ�·����ӳ�䵽AS����һ����·����ƥ�䷽����·����ƥ�䷽���Ļ���˼���ǣ�����ת��ƽ��·��������ƽ��·����һ�µģ�������traceroute ·������Ӧ��BGP AS Path (·��)��һ�µģ�����·�ɱ�����ȡǰ�����ķ���AS��Ϊ��ʼ��IP-to-ASӳ������������ʼ��ӳ������ڶ���ԭ���Dz�ȷ�ģ���[3]�з�����ԭ��·����ƥ�䷽������ͨ�����traceroute-BGP ·���Ե�������ȥ���������ʼӳ�������������Ե���·����ƥ�䷽����
[1]����ת��ƽ��·��������ƽ��·����һ�µļ��裬�����һ�ֶ�̬�滮�㷨����ͨ�����·����ƥ�䣬��/24ǰΪ���ȣ���������ʼ��IP-to-ASӳ��������dz�[1]�ķ���Ϊǰ���ȵ���������������/24��ǰ����ȥ����IP-to-ASӳ��Ķ�����������һ����С��ǰ���䵥λ��/24ǰ��Ȼ���������д����ķ�����ͬһ��/24ǰ�²�ͬ��IP��ַ����ӳ�䵽��ͬ��AS�š����磬�߽�·�����ϵ�ij���ӿڵ�ַ����ʹ�÷���������ھ�AS�ĵ�ַ�������/24ǰ�µľ��������ַ���DZ������ھ�ASʹ�ã��������罻���㣨IXP��Internet Exchange Point�������罻�����ǰ����û��һ������ӳ���AS�������г������IP��ַ�������ASʹ�ã�����AS�����ٸ�AS�����ڴˣ� [2]�����IP��ַ���ȵ�����������ͬ���ǻ���·����ƥ�䣬�Բ���[1]���㷨��ܣ�Ȼ����traceroute-BGP��·����ƥ���ϣ�������������ߡ�
��ȻIP��ַ���ȵķ�����ǰ���ȵ�����������·����ƥ����������������ߣ�Ȼ���Զ����������ַ����������ӣ�(1) ���һ�������ӳ����ǰ����ģ���ô��ǰ���ȵķ������Խ����/24ǰ�µ�����IP��ַ��ӳ�䶼������������ʹ��ЩIP��ַû�б�ѵ��������IP��ַ���ȵķ�������������ѵ����IP��ַ��ӳ�䣬/24ǰ�µ�������IP��ַ��δ��ѵ��������������������ϣ�ǰ���ȱ�IP��ַ���������ƣ�(2) Ȼ�����һ�������ӳ�����IP��ַ����ģ�ǰ�����ȵķ���Ҫô����������Ҫô�ͻ�����/24ǰ�µ�����IP��ַ��ӳ���Ĵ������������Ȼ��IP��ַ���������ơ�
Ϊ��ȫ��ķ���ǰ���Ⱥ�IP��ַ����������IP-to-ASӳ�䷽���ϵ����ӣ����������һ��ϵͳ���Ļ��ڷ������ķ�������������ϵͳ��ȫ��Ͷ������ķ���ǰ���Ⱥ�IP��ַ���ȵ����Ӽ��������ԡ�
���ĵ���֯�ṹ���£��ڶ��½����˱�����ص��о������������½����������ռ��ʹ����Ĺ��̡������½�����ǰ���Ⱥ�IP��ַ���ȵ�IP-to-ASӳ����������������������˷������ķ��������������»��ڷ������ķ���������������ʵ�����ۣ�ȫ��Ͷ������ķ���ǰ���ȵ�ӳ������������IP��ַ���ȵ�ӳ�����������������¶Ա��Ľ������ܽᡣ
2 ��ع���
����traceroute-BGP·����ƥ������������ع�����[4]ָ��IXP�ǵ���traceroute-BGP ·���Բ�ƥ�����Ҫԭ��[3]��ȫ��ķ�����traceroute-BGP ·���Բ�ƥ���ԭ������ʽ������IP-to-AS ӳ�䣬���˹���������[1]�����һ��ϵͳ��������IP-to-AS ӳ��ķ�����������/24ǰ��Ϊ���Ƚ����ġ�������꣬������[5][6]�ж�������traceroute-BGP ·���Բ�ƥ���ԭ��ͬʱҲ������[1]��ȱ�ݣ�����/24ǰ��������Ȼ���㹻��ϸ�����Ǽ����[1]��ȱ�ݣ� [2]�������һ��IP��ַ���ȵ�������������������·����ƥ��ȡ���IP��ַ���Ⱥ�ǰ���ȴӶ��Է����ϸ������ӣ������ľ���Ҫϵͳ����ȫ�滯��������ȥ��������������IP-to-ASӳ���ϵ����ӡ�
3 �����ռ�
�����ռ�����Ҫ�����ǣ�1����·�ɱ�����ȡ��ʼ��IP-to-ASӳ����������ʼ��ӳ����кܶ�Ĵ���ӳ�䣬��Ҫ����IP-to-ASӳ����������������������2���ռ�traceroute̽�������Ӧ��BGP·�ɱ���������traceroute-BGP ·���ԣ�IP-to-ASӳ��������������ͨ�����ƥ���·������������ʼ��ӳ�䡣��3������ѵ�����ݼ����������ݼ��ͱ�ӳ�䡣
3.1 ��ȡ��ʼIP-to-ASӳ���
���Ǵ�Routeviews[7]��RIPE[8]���ܼ�10���ռ�������2010��4��22��һ���ڵ�·�ɱ�����ȡ��·�ɱ���Ŀ��ǰ�ͷ���AS��������ǰ��AS��ӳ�䣬��������ǵij�ʼ��IP-to-ASӳ�����
3.2 ������traceroute-BGP ·����
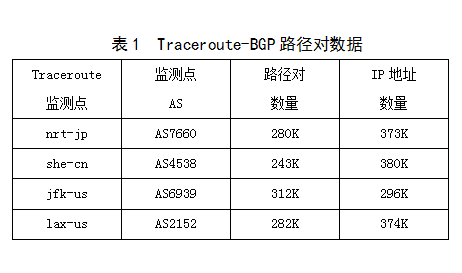
Ϊ���ܴ�����traceroute-BGP·���ԣ�������Ҫtraceroute�����BGP������ͬһ��AS��CAIDA[9]�������ĸ�traceroute���㣺nrt-jp (AS7660), she-cn(AS4538), jfk-us(AS6939)��lax-us(AS2152)������Routeviews[7]��RIPE[8]���ҵ���Щtraceroute��������AS��·�ɱ�������ʹ��2010��4��22�յ�Traceroute ���ݺ�BGP·�ɱ���������traceroute-BGP·���ԣ��õ���·���Եĸ�Ҫ��Ϣ���1��ʾ��������traceroute-BGP·���Եķ������£������ڶ�Ӧ��BGP·�ɱ��У�����traceroute·����Ŀ�ĵ�ַ���ƥ��ǰ���ƥ��ǰ��AS Path������traceroute·����Ӧ�Ŀ���ƽ���BGP AS Path����traceroute��IP��ַ�����·����·�ɱ����BGP AS·���㹹��һ��traceroute-BGP·���ԡ�
3.3 ����ѵ�����ݼ����������ݼ��ͱ�ӳ��
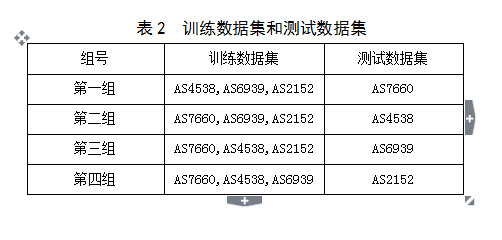
ͨ����һС�ڵĴ����������Ѿ�����������ĸ������traceroute-BGP ·���ԡ���һС�ڣ����ǽ���(1) ����ѵ�����ݼ�������ѵ��IP-to-AS ӳ�����(2) ������������ݼ�����������ѵ����IP-to-ASӳ�����ȷ�ȣ���ʹ�������ݼ���·���Դﵽ��ƥ���������ӳ�����ȷ�ȣ�(3) ��Ϊ�������ݼ������ӳ�������������Ϊ���ǵ���ȷ��ӳ�����
�������������������·������ѵ�����ݼ���ʣ��һ�������·������Ϊ�������ݼ������ɵõ�����ѵ���Ͳ������ݼ������2��ʾ�����в������ݼ����˴�Լ2% ��IP��ַ���ȵķ���Ҳ��ʹ��ƥ���·���ԣ��ⲿ��·���Ժܿ�����·�ɲ��ȶ��������������ռ����Ƶ����ص��µı����Ͳ�ƥ��Ļ���·���ԣ���Ϊ�ⲿ�ֻ���·���Դ�Լ50%���������ϵĴ�����Ȼ����������ͬ��traceroute·����BGP AS·�����ɵġ��������ϴ����IJ������ݼ�������������IP��ַ���ȵ��㷨���ɵõ�һ��IP-to-ASӳ�����ʹ�������ݼ�100%ƥ�䣬���IP-to-ASӳ��������dz�������
ӳ������������У�������ָ����ȷ��ӳ�����Ŀǰ���������ҵ���������ȷIP-to-ASӳ����ķ����������ĵķ�����Ҫ������ȷ��ӳ���������·����ƥ�䷽���ļ��裬����ֻ����·��ƥ���������IP-to-ASӳ�����ȷ�ԣ�Ҳ����˵ʹ·����ƥ���Խ�ߵ�IP-to-ASӳ������Ǿ���ΪԽȷ�����ڴˣ����ǰ����ǹ���ı�ӳ������ƿ�������ȷ��ӳ�������Ϊ���ǹ���ı�ӳ�������ʹ�������ݼ���·����100%ƥ�䣬û������ӳ����ܴﵽ���ߵ�·����ƥ��ȡ�
4 IP-to-ASӳ�䷽��
������4.1�н�����ǰ���Ⱥ�IP��ַ���ȵ�IP-to-ASӳ��������������4.2�ж����������ȵķ��������ӽ����˶��Եķ�����
4.1 ǰ���Ⱥ�IP��ַ���ȵ�IP-to-ASӳ����������
·����ƥ�䷽������ӳ���Ŀ���ǣ����·���Ե�ƥ�����������ǻ����������·����ƥ�����������Ž��㷨��ǰ���Ⱥ�IP��ַ���ȵ�IP-to-ASӳ������������������ʽ�ķ�����ǰ���Ⱥ�IP��ַ���ȵ������������㷨�������ͬ�ģ����ʵ���������ĵ����ȡ��㷨�Ŀ�ܶ���[1]�еĶ�̬�滮�ӵ��������Ŀ�ܡ�
�㷨����ǣ���������ÿһ��·�����ö�̬�滮�㷨�����ƥ�䣬���ƥ����ָ��traceroute·���ϵ�IP��ַƥ�䵽��Ӧ��BGP AS path��AS�ţ�����ʹ���IP-to-ASƥ���ϵ����ǰ��IP-to-ASӳ����������������IJ�һ�£�Ȼ���ۺ�ȫ����·���Ե����ƥ�䣬���߳�IP��ַӦ��ӳ�䵽��AS������뵱ǰ��ӳ�䲻��ͬ�������ӳ�������ӳ��������仯�������µ�ӳ���Ϊ��ʼ�㣬������һ�ֵ�����ֱ��ӳ���û�����仯Ϊֹ����ʼ��IP-to-ASӳ�����Ϊ��������ʼ�㡣
[1]�е�ǰ���ȵķ�����Ϊ�˻���ǰ���ȵ�ȱ�ݣ�����һ��/24ǰӳ�䵽���������ϵ�AS�ţ�����ᵼ��ӳ���ģ���ԡ������ص��������ǰ���Ⱥ�IP��ַ���ȵ����ӣ�Ϊ�˱�֤�ԱȵĹ�ƽ�ԣ������н��бȶԵ�ǰ���ȵķ�����ֻ����һ��/24ǰӳ�䵽һ��Ψһ��AS�����AS��ʹ·����ƥ�������Ǹ�AS��IP��ַ���ȵķ���Ҳͬ����ʹһ��IP��ַֻӳ�䵽һ��AS��
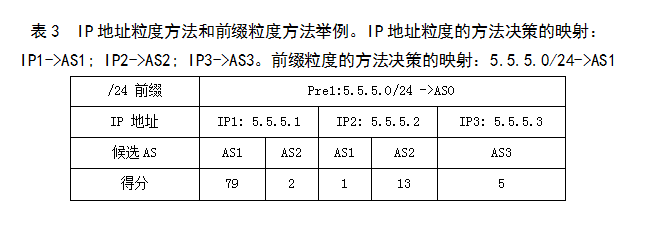
���ĵ��ص��Ƿ���IP��ַ���Ⱥ�ǰ���ȵķ��������ӣ��������㷨���������ڿռ����ޣ������������������Ľ�����Ҫ˵������ϸ�ķ���ϸ����μ�[1][2]��IP��ַ���Ⱥ�ǰ���ȵķ���һ�ε����������£�����Ϊ���е�·���������ƥ�䣬ͬһ��IP��ַ���ڲ�ͬ��·���������ƥ���AS���ܲ�ͬ��ÿ�����ƥ�����AS���Ǻ�ѡAS��Ȼ��Ϊÿ��IP��ַͳ�ƺ�ѡAS�ļ��ϼ���ѡAS�÷֡�һ��IP��ַ�ĺ�ѡAS���ϼ���IP��ַ������·���������ƥ���AS�IJ�������ѡAS�÷֣����ú�ѡAS�ڶ���·�����У��Ǹ�IP��ַ�����ƥ�䡣IP��ַ���ȵķ�����IP��ַ��/32ǰ��Ϊ������ӳ�䣬ÿ��IP��ַ��ѡ��ӳ�䵽���ĵ÷���ߵ��Ǹ���ѡAS��ǰ���ȵķ�����/24ǰΪ������ӳ�䣬ÿ��/24ǰ��ѡ��ӳ�䵽���ĵ÷���ߵ��Ǹ���ѡAS�����3����˵����IP��ַ���Ⱥ�ǰ���ȵķ����������ӳ��ġ���������Ա�3����һ�½��ͣ��ڱ�3����һ��/24ǰ: 5.5.5.0/24����ʼӳ��ΪAS0����ǰ��ѵ�����ݼ���������IP��ַ���ֱ�ΪIP1��IP��IP3������IP��ַ�ĺ�ѡAS���÷����3�ĵ����У���������ʾ��IP��ַ���ȵķ���ѡ���ӳ���ǣ�IP1->AS1; IP2->AS2; IP3->AS3����ǰ���ȵķ�������/24ǰΪ�����ȣ�5.5.5.0/24�ĺ�ѡӳ����AS1��AS2��AS3���÷�������79+1=80��2+13=15��5������ǰ���ȵķ���ʹ5.5.5.0/24ӳ�䵽�÷���ߵ�AS1��
4.2 ǰ���Ⱥ�IP��ַ�������Ӷ��Է���
ǰ���ȵķ�����ǰ�ϵ�IP��ַ����һ��ѵ������һ�ֽ���ϵķ�����IP��ַ���ȵķ��������ɢ��IP��ַ����ѵ������һ������ϵķ����������ַ����������ӣ����������з����ġ�����������ǰ����Ϊ����˵��ǰ���ȵ��ŵ�����㣬��֮�෴�ľ���IP��ַ���ȵ�������ŵ㡣���ѵ�����ݼ��Ͳ������ݼ����з�����ǰ���ȵ��ŵ���������£�
ǰ�������㣺ǰ���ȵķ�����/24ǰ�ϵ�IP��ַ����һ��ӳ�䵽ͬһ��AS�ţ���������ЩIP��ַ����ӳ�䵽������ͬ��AS�ţ�ǰ���ȵķ���������Щ�����IP��ַ��ӳ��������ȷ����IP���ȷ�����Ե���IP��ַ��������ȴ���ԡ�ǰ���ȷ����������������dz�Ϊǰ��ȱ�ݡ�
ǰ�����ŵ㣺���IP��ַ�ij�ʼӳ���Ǵ���ģ�����ЩIP��ַ����ѵ�����ݼ��У�ǰ���ȵķ�����24ǰΪ���Ƚ����ģ��������Խ�����һ����������IP��ַ���ȵķ�����IP��ַΪ���Ƚ���������ȴ�϶������ԡ�ǰ���ȵķ����������ŵ㣬���dz���ǰ�Ĵ��������ơ�
5 ��������������
���ǽ��������ݼ��е�IP��ַ���ڳ�ʼӳ�䡢ѵ��ӳ�䡢��ӳ����з����������ʼӳ�����ָ��·�ɱ�ֱ����ȡ������ǰ�ͷ���AS֮���ӳ�䣬����OM ��Original Mapping����ѵ��ӳ�����ָ��ǰ���ȵķ�������IP��ַ���ȵķ�������֮��õ���ӳ���������TM��Trained Mapping������ӳ�����ָʹ�������ݼ�100%ƥ���ӳ�䣬����SM��Standard Mapping����OM[IP]��TM[IP]��SM[IP]�ֱ�IP�ڸ��Ե�ӳ��ϵͳ��ӳ�䵽��AS�š�Pre[IP]����IP��/24ǰ��
����ԭ��1��IP��ַ�Ƿ���ѵ�����ݼ��У�����ǰ���ȵķ���������Ҫ����IP��ַ��/24ǰ�Ƿ���ѵ�����ݼ��У���2��IP��ַ��ӳ���Ƿ��ģ���TM[IP]�Ƿ����OM[IP]����3��IP��ַ��ӳ���Ƿ�����ȷ����TM[IP]�Ƿ����SM[IP]����4����ʼӳ���Ƿ���ȷ����OM[IP]�Ƿ����SM[IP]��
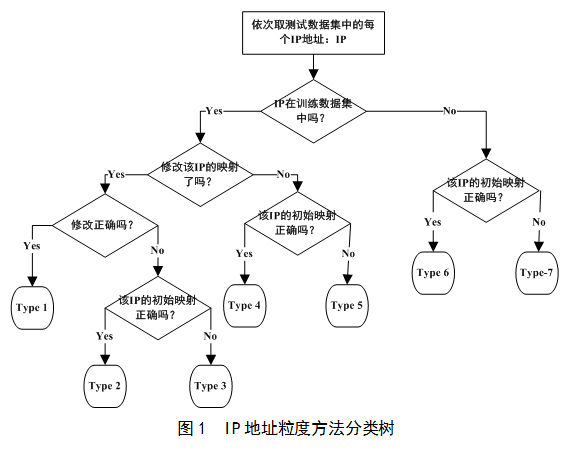
�������Ϸ���ԭ����IP��ַ���ȵķ��������Խ��������ݼ��е�IP��ַ�ֳ�7�࣬��ͼ1��ʾ������ǰ���ȵķ��������Խ��������ݼ��е�IP��ַ�ֳ�12�࣬��ͼ2��ʾ����ÿһ���͵�IP��ַ���Ƕ����������ֲ�������1��������Գ�ʼӳ������档��������е�IP��ַ���ó�ʼӳ�䣬Ȼ����Ӧ����IP��ַ�ij�ʼӳ���滻��ѵ���õ���ӳ�䣬ʹ�������ݼ��е�·������ߵ�ƥ��ȡ������ֵ�����ʾ����ڳ�ʼӳ�������ƥ��ȣ���ֵ���ʾ����ڳ�ʼӳ�併����ƥ��ȡ���Գ�ʼӳ������淴ӳ��ѵ������������ʼӳ��Ķ����٣�������Խ����ֵԽ��������ֵ�����������Խ�࣬�����ֵҲԽ���Ǹ�ֵ����2��������Ա�ӳ������档��������е�IP��ַ���ñ�ӳ�䣬Ȼ����Ӧ���͵�IP��ַ�ı�ӳ���滻��ѵ���õ���ӳ�䣬ʹ�������ݼ��е�·������ߵ�ƥ��ȡ����ڱ�ӳ��ƥ�����100%�������滻��ƥ��ȱ�Ȼ��Ȼͣ������涼�����ֵ������ڱ�ӳ������棬��ӳ��ѵ���������ж���ӳ��û��������������ܷ�������ÿ�����͵�IP��ַ�ĺ��塣
����IP��ַ���ȵķ������������и������͵ĵĺ������£�
?����1��IP��ַ��ѵ�����ݼ��У���ʼӳ���Ǵ���ģ��������ģ�������ȷ��
?����2��IP��ַ��ѵ�����ݼ��У���ʼӳ������ȷ�ģ������Ĵ����ˡ�
?����3��IP��ַ��ѵ�����ݼ��У���ʼӳ���Ǵ���ģ��������ģ���û����ȷ��
?����4��IP��ַ��ѵ�����ݼ��У���ʼӳ������ȷ�ģ�δ������
?����5��IP��ַ��ѵ�����ݼ��У���ʼӳ���Ǵ���ģ�δ�����ġ�
?����6��IP��ַ����ѵ�����ݼ��У���Ȼû��������ӳ�䣬��ʼӳ������ȷ�ġ�
?����7��IP��ַ����ѵ�����ݼ��У���Ȼû��������ӳ�䣬����ʼӳ���Ǵ���ġ�
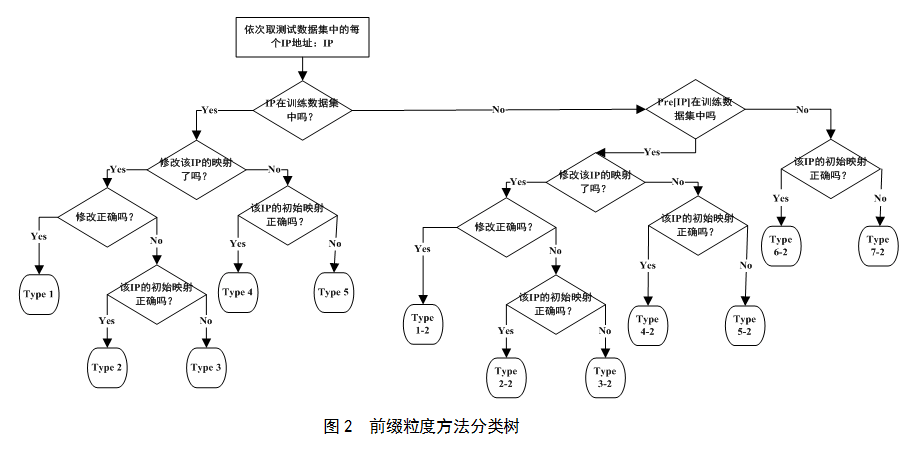
��ǰ���ȵķ����ķ������У�����1������5��IP��ַ���ȵķ����ĺ�������ͬ�ġ�����1-2������7-2ʵ���ϸ���/24ǰ�Ƿ���ѵ�����ݼ��У���IP��ַ���ȷ���������6������7�Ľ�һ��ϸ�֡�����1-2������7-2�ĺ���������ʾ��
?����1-2��IP��ַ����ѵ�����ݼ��У�������/24ǰ��ѵ�����ݼ��У���ʼӳ���Ǵ���ģ��������ģ�������ȷ��

6 ʵ������
��������������ѵ�����ݼ��зֱ�����ǰ���ȵķ�����IP��ַ���ȵķ������õ����Ǹ���ѵ����IP-to-ASӳ�������ʱ��ʼӳ�����ѵ��ӳ����ͱ�ӳ����Ͷ����ˡ�Ȼ�����÷������ķ������������������ݼ��е�IP��ַ���з��࣬���ֱ�Ϊÿһ���͵�IP��ַ��������Գ�ʼӳ����������Ա�ӳ������档
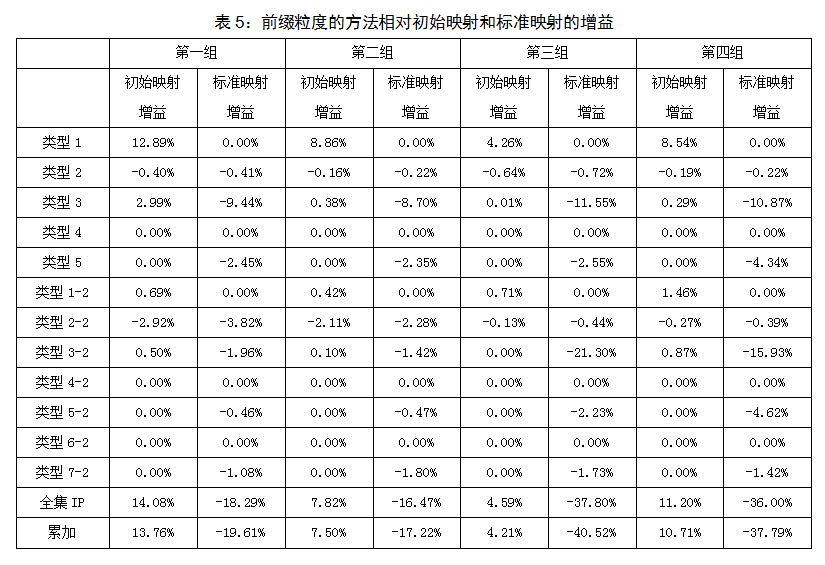
����IP��ַ���ȵķ��������ǿ��Խ��������ݼ��е�IP��ַ�ֳ�7�࣬������ǰ���ȵķ��������ǿ��Խ��������ݼ��е�IP��ַ�ֳ�12�ࡣ���յ�5�£���ʼӳ������ͱ�ӳ������ļ��㷽�������Ƕ�IP��ַ���ȵķ�����ǰ���ȵķ������ֱ�Ϊ��������IP��ַ��ѵ�����ӳ�䣬������Գ�ʼӳ��ͱ�ӳ������棬���4�ͱ�5��ʾ����Ԫ���ڵ�ֵ���Ƕ�Ӧ���͵�IP��ַ����Գ�ʼӳ����ӳ������档��ע�⣺���������·���ԣ�����ָ�������ݼ��е�·���ԣ�������ѵ�����ݼ��е�·���ԣ���
���ǽ���һ�±�4�ͱ�5�е����������ֶεĺ��塣��ȫ��IP����ָ�Ƚ��������͵�IP��ַ�������������Լ���IP��ַȫ������������������档���ۼӡ���ָ�ȶԵ������͵�IP��ַ�����棬Ȼ���ٽ���������IP��ַ����������ۼӡ��ۼӡ���ֵ��С�ڡ�ȫ��IP����ֵ������Ϊ��Щ·���ԵIJ�ƥ������������ͬ�������ϵ�IP��ַ���µģ���ȫ��IP�������������ǣ������������͵IJ����ԡ���ȫ��IP���͡��ۼӡ���ֵ�����˵�����������ƥ���·��������ͬһ�������ڵ�IP��ַ���µġ�������ʵ���Ͼ������·���ԵIJ�ƥ�����һ��������IP��ַ���µģ���Ϊ��Լ80%�IJ�ƥ���·���Խ���һ������
���ĵļ�����ת��ƽ��·�� (Traceroute·��)������ƽ��·�� (BGP AS Path)��һ�µģ�����������裬IP-to-ASӳ��ʹtraceroute-BGP·����ƥ���Խ�࣬�����Ǿ���Ϊ���ӳ���Խȷ����Ϸ���������Գ�ʼӳ��ͱ�ӳ������棬���������¼�����������1��������ǰ���������IP��ַ���ȵ����ơ���2��������ǰ���������IP��ַ���ȵ����ơ���3��ǰ���Ⱥ�IP��ַ�������ϵķ����Ƿ����á���4���������͵ķ�����
Ϊ�������������Ƕ������¼���������
?I_O(Type i): ��IP��ַ���ȵķ���������i��IP��ַ�ij�ʼӳ�����档
?P_O(Type i): ��ǰ���ȵķ���������i��IP��ַ�ij�ʼӳ�����档
?I_S(Type i): ��IP��ַ���ȵķ���������i��IP��ַ�ı�ӳ�����档
?P_S(Type i): ��ǰ���ȵķ���������i��IP��ַ�ı�ӳ�����档
6.1 ������ǰ���������IP��ַ���ȵ�����
��һ��/24ǰ����ʼӳ��ΪA��ǰ���ȵķ��������/24ǰ��ӳ����������B����ǰ�ϵ�һ��IP��ַ��IP1����Ӧ��ӳ�䵽C���������ǰ�İ�ȱ�ݣ�Ҳ����IP1����ӳ���ij���B�������ڷ�������IP1��Ӧ����3��IP��ַ������ѵ�����ݼ��У���ʼӳ���Ǵ���ģ�ѵ����������ӳ��������ĵ�û������ȷ���������ǰ�ϻ���һ��IP��ַ��IP2����Ӧ��ӳ�䵽A��Ҳ����˵��ʼӳ�䱾��������ȷ�ģ���ǰ���ȵķ���ȴ����Ľ�����ӳ���ij���B����IP2�������ڷ������ж�Ӧ����2������2-2��
��һ��/24ǰ����ʼӳ��ΪA����ǰ���ȵķ���ѵ�����Ա��ָ�/24ǰӳ�䵽��ʼ��A��������һ��IP��ַ��IP1����Ӧ��ӳ�䵽B���������ǰ�İ�ȱ�ݣ�û�ܽ����ij�B����ʹ���dz�ʼ��ӳ��A����IP1�������ڷ�������������5��
����3-2������5-2ͬ����3������5����ͬ�����������δ����Щ��������ǰ�İ�ȱ�������Ϊ����3-2������5-2��IP��ַ����������ѵ�����ݼ��У���ʹIP���ȵķ���Ҳ���������ǣ���Ϊ�������������Щӳ�����Ϣ�����������ѵ�����ݼ�������ֵ�ԭ���µģ�����������ǰ��ȱ�ݵ��µġ������� 2-2ȴ����������ǰ��ȱ�ݣ�����Ϊ�䱾����ӳ������ȷ�ģ���ǰ���ȵķ���ȴ�������Ĵ����ˡ�
�������������ȵķ�������ڱ�ӳ��IJ�����������������3������5������2�IJ�ࡣIP���ȵķ���������2-2�ϵ�ӳ�伴��ʼӳ�䣬Ҳ�DZ�ӳ�䣬���Կ���ǰ���ȵķ�������ڳ�ʼӳ�����������������������2-2�ϵIJ�ࡣ
����ǰ���ȵķ��������IP��ַ���ȵķ��������ƣ���·�����������Ļ������㹫ʽΪ��I_S(Type 3) - P_S(Type 3) + I_S(Type 5) - P_S(Type 5) + I_S(Type 2) - P_S(Type 2) - P_O(Type 2-2)��
��������ļ��㹫ʽ������Ϊ�������ݼ��ֱ����ǰ���ȵķ��������IP��ַ���ȵķ��������ƶ���ֵ�������ǣ�12.15% (��һ��), 8.84% (�ڶ���), 11.24% (������), 13.80% (������)��
�����ܺ͵Ķ���ֵ֮�⣬���ǻ����������͵�ǰ��ȱ�ݽ����˵�����������ֵ��ǣ�Ψ��������2�ϣ�IP��ַ���ȵķ���������ǰ���ȵķ����������IP��ַ���ȵķ��������ӳ��IJ�����ǰ���ȵķ��������ӳ��IJ�ࣩ��������ΪIP��ַ���ȵķ�����ǰ���ȵķ�����Ҫ�������У��ᵼ�½϶���Ĵ����ӱ�4�ͱ�5���Կ�����������dz���С�����⣬���ǻ�����ǰ��ȱ�ݵ�������Ҫ����������3�ϣ�������2������5�ı����dz�С��Ϊʲô������������Ҫ���и���������о����������Է���һЩ�µ�����
6.2 ������ǰ���������IP��ַ���ȵ�����
��һ��/24ǰ����ʼӳ��ΪA�������/24ǰ��ӳ����������B����ǰ�ϵ�һ��IP��ַ��IP1������IP1��ҲӦ��ӳ�䵽B������IP1������ѵ�����ݼ��У�IP��ַ���ȵķ�����Ȼ��������IP1����ӳ�䣬��ǰ���ȵķ������ԡ���IP1�������ڷ�������������1-2��IP��ַ����ѵ�����ݼ��У�������/24ǰ��ѵ�����ݼ��У���ʼӳ���Ǵ���ģ��������ģ�������ȷ����
���ԣ�ǰ���ȵķ��������IP��ַ���ȵķ��������ƣ���·�����������Ļ�������ǰ���ȵķ���������1-2����Գ�ʼӳ�������������������P_O(Type 1-2)�����������ݼ��У�ǰ���ȷ��������IP��ַ���ȷ������ƵĶ���ֵ�����ǣ�0.69% (��һ��), 0.42% (�ڶ���), 0.71% (������), 1.46% (������)��
6.3 ǰ���ȷ�����IP��ַ���ȷ������ϵ�ӳ���Ƿ�����
���ڽ��ش�������⣺��ǰ���ȷ���������/24ǰ���ȵ�ӳ���IP��ַ���ȷ���������/32ǰ(IP��ַ)���ȵ�ӳ������һ���Ƿ����á�
��ǰ���ȵ�ӳ���IP��ַ���ȵ�ӳ������һ�𣬲����ǰƥ��ԭ����һ��IP��ַ��ӳ�������ƥ��/32��ǰ(IP���ȷ�����ӳ��)����û��ƥ���/32ǰ���ٲ���/24ǰ���ȵ�ӳ�䡣��������ѵ�����ݼ��е�IP�������IP����������ӳ�䣬�Բ���ѵ�����ݼ��е�IP�����ǰ����������ӳ�䡣
Ȼ���Բ���ѵ�����ݼ��е�IP��ַ��ǰ���ȵķ����ȿ��ܽ������ӳ��������ȷ����Ӧ����������1-2������Ҳ���ܽ�������ȷ��ӳ���Ĵ���Ӧ����������2-2�����ۺ���˵���������ȵķ������ϵ�ӳ���Ƿ��IP���ȷ���������ӳ��Ч���ã�ȡ����P_O (Type 1-2) + P_O (Type 2-2)��ֵ����Ϊ��ֵ����˵���������Ƚ����������ã�����˵���������Ƚ�������������IP��ַ���ȵġ�
�ӱ�5���Կ�������һ��͵ڶ������ݼ���ǰ���ȷ�����IP��ַ���ȷ������ֽ�ϵ�ӳ�䲻���IP��ַ���ȵķ���������ӳ�䣻��������͵��������ݼ���ǰ���ȷ�����IP��ַ���ȷ������ֽ�ϵ�ӳ��Ҫ���ڽ�IP��ַ���ȵķ���������ӳ�䡣���Խ�/24ǰ���Ⱥ�IP��ַ������Ȼ�Dz��㹻�ģ�Ӧ��̽�����ֲ�ͬ���ȵ�ӳ���������������ʵ�������ȥ������Ӧ��ӳ�䡣
6.4 �������ͷ���
����1��ӳ�˷�������ӳ�����������Գ�ʼӳ�������Խ��˵����������ӳ��Խ�ࡣ�ӱ�4�ͱ�5���Կ�����������1��Գ�ʼӳ��������ϣ�IP��ַ���ȵķ�����ǰ���ȵķ���Ҫ�߳�7.07%~12.43%��·����ƥ�䡣����1-1�����Է�ӳǰ���ȵķ�����������ѵ�����ݼ��е�IP��ַ��ӳ���������IP��ַ���ȵķ���û�������������ǰ���ȷ�������������dz�С����������0.42%~1.46%��·����ƥ�䡣
�ӱ�5���ǿ��Կ�����ǰ���ȷ������д����ģ�1.42%~21.30%����ƥ���·���Լ���������3-2������3-2������3���ƣ�����3-2��IP��ַ��ӳ�������/24ǰ������ӳ�䲻һ�£����Լ�ʹ����ѵ�����ݼ��У�ʹ����3-2��IP��ַ������ѵ�����ݼ��У�ǰ���ȵķ�����Ȼ����Ϊǰ���ȵİ�ȱ�ݶ����������ǣ�ֻ����IP��ַ���ȵķ����ſ��Ժܺõ��������ǡ�ͬ��������5-2Ҳ����ˣ�ֻ������5-2��Ӧ����ƥ���·���Ա�����С��
����4������4-2������6�dz�ʼӳ�����ȷ��IP��ַ����ѵ������Ȼ������ȷ����ӳ�˷����������ԡ�
7 ����
����ͨ��������������ϵͳ��ȫ��ķ�����/24ǰ���ȵ�����IP-to-ASӳ�䷽����IP��ַ���ȵ�����IP-to-ASӳ�䷽����ǰ���ȵķ�����ͬһ��/24ǰ��IP��ַ����һ��ӳ�䵽ͬһ��AS����ǰ���ȷ��������ְ�ȱ���ϣ���·����ƥ����������Ļ���ǰ���ȵİ�ȱ�ݵ��� 8.84%~13.80%��·����ƥ����ʧ����ǰ���ȵķ�������������ѵ�����ݼ��е�IP��ַ��ӳ�����������ǰ���ȷ��������ִ����������ϣ���·����ƥ����������Ļ���ǰ���ȵĴ��������ƿ�������0.42%~1.46%��·����ƥ�䡣�ɴ˿ɼ���ǰ���ȵİ�ȱ��ԶԶ����ǰ���ȵĴ��������ƣ���֮��Ӧ�ģ�������ӳ��������ϣ�IP��ַ���ȷ�����ȻԶԶ����ǰ���ȷ�����
�����
[1] Z. M. Mao, D. Johnson, J. Rexford, J. Wang, and R. H. Katz, ��Scalable and accurate identification of AS-level forwarding paths,�� in Proc. INFOCOM 2004, 2004.
[2] Baobao Zhang,Jun Bi, Yangyang Wang, Yu Zhang, Jianping Wu, ��Revisiting IP-to-AS mapping for AS-level traceroute��, in Proc. CoNEXT 2011 Student Workshop, December 2011
[3] Z. Morley Mao, Jennifer Rexford, Jia Wang, and Randy Katz, ��Towards an Accurate AS-level Traceroute Tool,�� in Proc. SIGCOMM, September 2003.
[4] Y. Hyun, A. Broido, and kc claffy, ��Traceroute and BGP AS path incongruities,�� CAIDA, Tech. Rep., 2003.
[5] Yu Zhang, Ricardo Oliveira, Hongli Zhang, Lixia Zhang , "Quantifying the Pitfalls of Traceroute in AS Connectivity Inference", in Proc. PAM 2010, April 2010.
[6] Yu Zhang, Ricardo Oliveira, Yangyang Wang, Shen Su, Baobao Zhang, Hongli Zhang, Lixia Zhang, "A Framework to Quantify the Pitfalls of Traceroute in AS-level Topology Measurement", IEEE Journal of Selected Areas in Communications (JSAC), 2011, 29(9): 1822 - 1836
[7] BGP routing tables: http://archive.routeviews.org/
[8] BGP routing tables: http://www.ripe.net/data-tools/stats/ris/ris-raw-data
[9] Traceroute probes: https://topo-data.caida.org/team-probing/












 ��ϲ�㣬�����ɹ�!
��ϲ�㣬�����ɹ�!

 !
!