手机看新闻
手机看新闻 分享到人人
分享到人人摘 要:为了能对一段短视频提供语义上有意义的表达,本文提出了一种能同时刻画可重构能力和多样性的结构化的L2,1优化模型。为了防止相似的样本被同时选中,该模型加入了互抑制惩罚项。在互抑制因子的选择方面,该模型有高度的灵活性,本文中,我们加入了视频中的时序信息来保证结果的多样性。对于本文中非凸的目标函数,我们推导出一个迭代算法,来解决这个优化问题。我们运用多个Youtube上的片段和室内的移动机器人拍摄的视频来做性能评价。实验结果明确地显示出,相比于其他当前的方法,本文的策略能使优化模型得到更加多样化的关键帧。
关键词: 视频内容分析,关键帧选择,结构化L2,1优化,互抑制
I.引言
随着数字相机和智能手机的流行,与以前相比,现在人们采集和存储的视频片段越来越多。这样大规模的视频片段集合很难去直观地浏览[1]。自动关键帧提取,对于视频检索,浏览,组织[2][3],以及视频监控[4][5],动作识别[6]变得非常重要。这样的技术也能够用来为因特网上的图片集以及图片数据集做摘要[8]。自动关键帧提取的主要困难就是如何在保留原始视频基本内容的前提下抽取视频帧。
关键帧选择也在机器人方面扮演着重要的角色。文献[9]用选出的关键帧来形成一个视觉路径和一个2维的视觉伺服让移动机器人从现在的位置移动到下一个关键帧。在[10]中,关键帧由一个位置序列上的图片组成并用来估计场景的几何结构。在文献[11]中,机器人通过将当前帧与之前帧的子集进行匹配来检测位置和地图的闭环[12]。除此之外,关键帧对构建3D模型和增强现实系统非常有用。文献[13]选择关键帧来为增强现实应用做完全捆绑调整。文献[14]选择更小数量的关键帧来形成一个骨干子集,这个子集分布于整个数据集并且能够产生相当准确的重构。文献[15]描述了一个并行的跟踪和匹配系统,这个系统同时对视频流中选出的关键帧运用完全捆绑调整,对中间帧能够产生鲁棒的实时位置估计。在这些所有的应用中,关键帧被当作相应数据集的代表,在降低运算规模方面扮演着重要的角色。
在过去的20年中,关键帧提取虽然被大量地研究过,许多之前的方法主要是针对结构化的视频,比如会议[16],监控[17]和体育[18]。在[19]中,作者开发了一个视觉识别系统完成了抓取的摘要任务。运用Zernike范数,局部的最小最大值就能够表明用来选择关键帧的新的视觉事件。这个方案没有设置阈值,所以提取出的关键帧的数量随着运动能量的变化复杂度而改变。不管怎样,这个方法依然关注于高度结构化的视频。非结构化视频,如消费类视频或者移动机器人采集的视频的关键帧提取依然是一个非常有挑战性的问题。正如文献[20]所说明的,在消费类视频中,场景的变化是没有约束的。与专业的电影和体育视频不同的是,这些视频没有专业的编辑,一个视频片段往往只包含一个镜头(所以,镜头检测并不需要)。消费类视频最大的挑战就是其非结构化的内容而且没有任何预先设定结构[20]。
另一方面,稀疏编码和字典学习在信号处理领域已经变成非常活跃的主题而且已经被成功地运用到非结构化视频的关键帧提取中。文献[21]通过组稀疏优化来研究消费短视频的关键帧提取。最近,文献[22]研究了类似的模型并且分析了选出的代表的几何性质。两个工作都运用了视频帧的自我表达特性[24]。这些方法的优点就是,他们能够产生任何数目的关键帧并且提供排序好的输出结果,这在实际应用是一个非常想得到的特点。因此,在改变设置如关键帧数目时并不会产生额外的复杂度。
不幸的是,由于缺少结构化信息,这种方法仍然在可靠并自动地通过稀疏编码系数选择关键帧方面有困难。为了解决这个问题,经常用基于非最大抑制的后处理模块来选取关键帧。然而,由于两个步骤是分开进行的,这种初级的方法可能会降低关键帧的质量。除此之外,这些方法独立地对待视频帧并且忽略了选出关键帧的依赖关系。所以,连续帧之间的时序联系不能够被利用。最近,文献[25]用不相似性来选择关键帧。但是,关键帧的重构能力不能保证。此外,一些跟正常帧显著不同的不正常帧非常容易被选为关键帧。
虽然稀疏编码方法适合为消费类视频片段做摘要,一个重要的事实---选出的关键帧不应该太近,而且应该尽可能包含所有的序列---还没有被加入到现有的稀疏优化模型中[22][23]。这篇论文提出了结构化的优化模型来选择关键帧。这个模型的目标就是克服前面稀疏编码模型的弱点。与他们不同的是,我们的方法显式地包含了图片帧的依赖关系,并且用互抑制因子来获得更加多样化的关键帧。
这篇论文的主要贡献概括为一下三点:
1)提出一个同时刻画重构能力和多样性的结构化L2,1优化模型。在这个模型中,加入互抑制惩罚项来防止相同的样本被同时选中从而使结果更加多样。
2)提出的方法能够很灵活地包含不同的互抑制因子。在本方法中,这个因子用简单的时序依赖而不是复杂的相似性测度来构造。
3)提出一个迭代算法来解决优化问题并产生排序的帧列表,从中我们能够很容易抽取关键帧。
本文剩下的部分组织如下:小结II描述了问题建模,并给出了优化模型的细节;小结III介绍了优化算法;小结IV讨论了我们的方法与其他方法的不同;小结V给出了实验结果;小结VI给出了结果。
II.问题建模
文献[3]提到,关键帧可以看作是一组从源视频中提取出的图片集合。所以,关键帧选取的过程就等价于在一定的约束下怎样从整个视频的帧池中选出一个最优的子集。考虑一个矩阵。
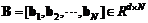 , (1),
, (1),
每个列向量代表一个视频帧的特征向量。我们的任务就是在满足一些性能指标的情况下,找到一个最优子集
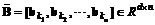 , (2)
, (2)
其中。也就是说,关键帧提取的过程等价于解决如下的优化问题
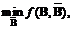 (3)
(3)
其中,是优化目标函数。很显然,不同的会导致不同的关键帧提取结果。
在许多实际的应用当中,关键帧应该是所有视频帧的代表,比如,一个样本应该是的线性组合。为了刻画这种重构能力,在用关键帧重构整个视频序列的时候,下面的代价函数应该被最小化:
 (4)
(4)
其中是矩阵的Foubenious范数,是系数矩阵。需要指出的是,这不是关键帧选取时候目标函数的唯一选择。
现在的问题是,系数矩阵和索引集都是未知的。所以我们用的所有列来表示本身,也就是我们应该找到满足
 (5)
(5)
除此之外,关键帧的数量应该尽可能少。为了解决这个问题,一个直接的方法就是最小化如下的目标函数
 (6)
(6)
其中用来平衡不同的惩罚项。第一个式子用来评估重构误差,没有第二个式子的时候,无约束的优化将会导致平凡解。第二个式子表示为
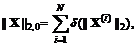 (7)
(7)
其中是Dirac操作符,表示的第i行,代表非零行的数目,将L2,0范数加入目标函数中,能避免得到平凡解,而且能保证结果是行稀疏的(大部分行都是零向量)。但是,这样的优化问题是一个NP难问题,得到它的解需要进行组合搜索,随着维数N的增加,组合搜索的规模增长速度超过了多项式速度。通常的做法使用L2,1范数代替L2,0范数,得到如下的凸优化问题
 (8)
(8)
其中
 (9)
(9)
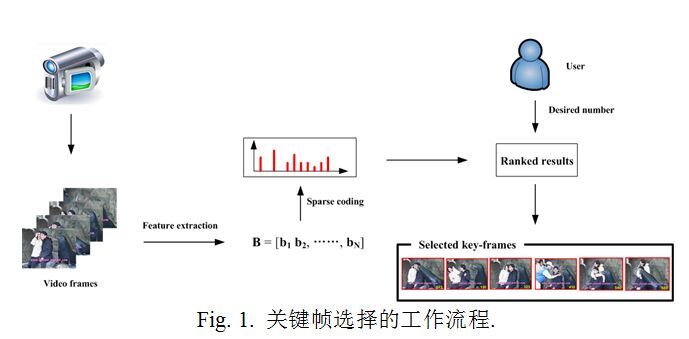
是每一行L2范数的和。公式(8)所表示的优化问题能够用梯度法或者乘子交替方向法高效地解决。得到的值后,用来表示第i帧是关键帧的可能性。如果是行稀疏的,也就是大多数行是零向量,那么我们就可以选择非零行对应的帧作为关键帧。这样看起来已经为关键帧选取铺平了道路。图1表示关键帧抽取的工作流程。首先,从每个视频帧中抽取特征向量形成矩阵。然后,运用稀疏编码方法得到系数矩阵和对应于第帧的结果权重。基于权重曲线,我们可以得到排序的结果,其中。最后,基于用户设定的关键帧数量,就是选出的关键帧。
不幸的是,在实际当中,接近于零但是不为零,因此需要一个精心设计的后处理模块。常用的方式是生成一个用生成一个权重曲线,然后检测权重的局部最小值来选取关键帧[22][23]。
虽然(8)所表示的模型是有效的,但是它仅仅刻画了重构性和稀疏性,而没有考虑关键帧应该是各不相同的。结果就使选取出的关键帧在时间上非常不均匀,而且有些时候会非常接近。为了解决这个问题,[22]和[23]都设计了后处理模块来弥补多样性的不足。因为稀疏编码和多样化平台是分开进行的,稀疏编码的原始结构有可能被破坏,进而影响关键帧提取的性能。除此之外,后处理模块的引进使设计流程更加复杂。
正如上面所提到的,关键帧提取的目标是找到一个能够包含视频主要内容并有充分多样性的的子集。这项研究也假设中的每一帧都是关键帧的候选,而且相似的帧不能被同时选为关键帧。为了达到这个目标,关键帧选取能够表示为如下的新的优化模型。
 (10)
(10)
和用来平衡不同的惩罚项。第三个部分被称为是互抑制项,是用来防止相似的样本同时被选中。权重矩阵在刻画抑制作用是扮演重要的角色。基本地,它能决定用户寻找的互抑制的程度。用户可以为每一个样本对定义一个。如果和相似,那么就可以赋一个比较大的值给。否则,可以赋比较小的值。尽管有很多相似性的测度可以用来设计稀疏矩阵,在这里我们用视频中内在的时序依赖来刻画。这样没有引起多余的计算。
对于一般的视频序列,多样性可以表达为被选中的关键帧不应该太接近。因此,相应的惩罚项应该用来加强被选中关键帧位置的时序关系。特别地,他们的位置不能太接近,因为学出的关键帧被期望是多样化的,所以他们分布在视频中很大的范围内。准确地讲就是,如果第i帧被选为关键帧,那么,包含于区间的帧就有很小的可能性被选中,除非帧的内容差异很大,其中是预先设定的窗口宽度。为了方便,表示与i最接近的个视频帧序号,但不包含i。这个定义考虑了边界。例如,如果, , 那么, , , . 如果,那么和会避免被同时激活。这样做能使关键帧分布更加均匀更加多样。为了刻画这个特性,横向抑制被用来刻画关键帧的多样性。横向抑制源于皮质表达,最近被用于结构化稀疏编码[27]。然而,[27]中的工作仅限于L1优化问题,不同于本文中的L2,1优化问题。除此之外,[27]中的工作关注字典学习,不同于本文的字典选择问题。字典学习和字典选择最核心的不同是为了构造字典前者从样本集中构造出了新样本,后者从样本集中选择样本来构造字典。没有明显的方法从文献[27]学到的字典中提取关键帧。很显然,字典选择对于关键帧选取是更加合适的方法。
根据上面的陈述,抑制矩阵如下
 (11)
(11)
新建立的互抑制因子加入了时间距离的影响因素,有更大的可能性使得到的关键不会靠得很近。
总结起来,新提出的结构化稀疏编码方法有如下优点:
1)通过新加入互抑制惩罚项,新的优化模型同时刻画了关键帧的重构性和多样性。之前的[22][23]工作中,这两个特性是被单独处理的。
2)新提出的模型能够很灵活地加入不同的互抑制项。在本文中,我们用内在的时间依赖来设计一个特定的抑制矩阵。这样就形成了一个简单又有效的优化模型。
3)因为结构化的信息已经加入到了优化目标中,得到的结果对惩罚参数就是不敏感的。这会在实验部分更加深入地阐述。具体说来,在模型(8)中,系数和稀疏模式都会对折衷参数敏感。然而,在新提出的模型中,只有系数对折衷参数敏感,稀疏模式却是鲁棒的。这是一个非常令人渴望的特性,因为稀疏模式正是用来选择关键帧的。
Remark 2.1:如果窗口宽度的值足够大,公式(10)中的稀疏项是不需要的,因为互抑制项也可以导致行稀疏。然而,太大的没很好地刻画关键帧的结构,会导致情节丢失。当在区间[5, 10]时,结果一般不会有太大变化。所以,的值设为10。这时,行稀疏项是必要的,而且公式(10)中的第三项变为。
Remark 2.2:这项工作的目标是通过加入互抑制项来提高关键帧的多样性。因此,没有别的策略来优化特征提取。不同的特征设计会导致不同的关键帧选择结果。怎样为视频设计合适的特征是和任务相关的,已经超出了本文讨论的范围。本文中,我们用[22]中描述的特征来表示图片。如果需要,也可以在不改变其他框架的情况下,用文献[28]中的局部方向特征来代替。
III.优化算法
公式(10)的目标函数是非凸的,所以我们应该求助一些精心设计的算法来解决。公式(10)中的优化问题可以等价地转化为
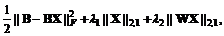 (12)
(12)
其中是一个对角矩阵,第i个对角元素如下
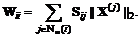 (13)
(13)
如果固定,上述的优化问题可以看作是一个带权重的L2,1优化问题。通过文献[26],上述问题能够通过迭代地最小化如下的目标函数解决:
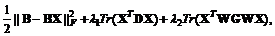 (14)
(14)
其中是矩阵的秩,是一个对角矩阵,第个对角元素为
也是对角矩阵,第个对角元素为
需要说明的是,在实际中,和会非常接近零。在本文中,我们可以按照传统的重整化方法定义和的元素分别为和,其中是一个很小的常量。
令公式(14)的导数为零得到
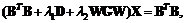 (15)
(15)
那么就可以表示为
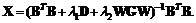 (16)
(16)
不幸的是,因为,和是依赖,公式(16)没有给出的闭式解。
为了解决这个问题,算法1阐述了一种迭代方法。当目标函数值变化可以忽略时就可以终止。尽管上述优化模型是非凸的,也没有任何正规的终止条件,但是在实际中,该迭代算法效果很好。

得到之后,我们可以用对视频帧进行排序。越大,这个帧越重要。用户可以设定关键帧的数量,也可以设定一个阈值,选择超过这个阈值的帧作为关键帧。要申明的是,在本方法中[22]和[23]没有其他的后处理模块。
因为(10)所示的模型是一个非凸的优化问题,一些启发式和先进的人工智能优化算法(如进化计算)可以用来找全局最优解。然而,在实际当中,这种简单的迭代算法更加有效。这样的迭代算法对于工程师和项目参与者也容易理解和实现。
浮点数运算是本算法中主要的开销,计算时间与数学操作的次数成正比。为了评估时间复杂度,我们统计了每次循环内需要的加法,乘法和函数求值的次数。例如,算法中第三第四行。在算法1的第三行,可以预先计算好。和是对角矩阵,所以需要4N次乘法和次加法。矩阵求逆需要次乘法和次加法。如果每一次操作都当作一次浮点数运算,那么第三行的浮点数运算总数是。算法1的第四行,的计算需要N次乘法,加法,和一次开方运算。得到中的一个对角元素需要一次乘法和一次除法。所以计算需要次浮点数运算。的计算很简单,,其中是的第个对角元素。所以,得到只需要次除法和次乘法。对于,第个对角元素是,需要次加法和次乘法。所以,第四行浮点数运算的总数是。总结起来,每一次迭代,浮点数运算的总数是。算法1的过程中,只需要三个打得数据结构, 和。,和是对角的,所以只需要三个维向量。
IV.与当前工作的区别
本小结分析了我们的工作与一篇相关的文献模型的不同。在文献[8]中,图片摘要被描述为下面的优化模型:
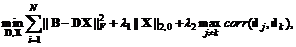 (17)
(17)
其中是学出的字典,是多样性函数,是用关系定义的(详见文献[8])。很显然,这个模型也可以用来做视频关键帧选取。然而,与我们的模型有两方面的不同:
1) (17)中所示的模型是难解的,有以下三个原因:(i) 字典是从候选中得到的,所以搜索空间是离散的。(ii) 稀疏性是用L2,0来施加的。(iii) 复杂的多样因子增加了挑战。为了解决这个模型,文献[8]不得不求助模拟退火算法(一种启发式优化算法)。尽管这种优化算法应该被用来搜索全局最优解,文献[8]中的作者声称模拟退火算法不能保证全局最优解每次都被找到。相比之下,本文提出的模型,搜索空间是连续的。此外,我们用互抑制项来刻画多样性,更具有明确的物理意义。最后,L2,0范数放松为L2,1范数。这样就可以用高效的迭代算法来解决这个问题。
2)文献[8]将图片集摘要问题公式化为一个联合优化问题。在运行模拟退火算法之前参数需要确定下来。也就是说,万一用户想改变关键帧的个数(如果我们提供了人机接口,这个会经常发生),那么整个算法就要重新运行来输出新的结果。这样会导致一种非常不希望见到的现象,不同的会有完全不同的关键帧选择结果。相反,本文的方法很容易避免这个问题。一旦优化过程结束,拍好序的结果就可以被输出出来。所以,在改变关键帧个数的时候,本文的方法能够在不增加额外开销的情况下产生需要的结果。这正是实际应用中期望的特性。
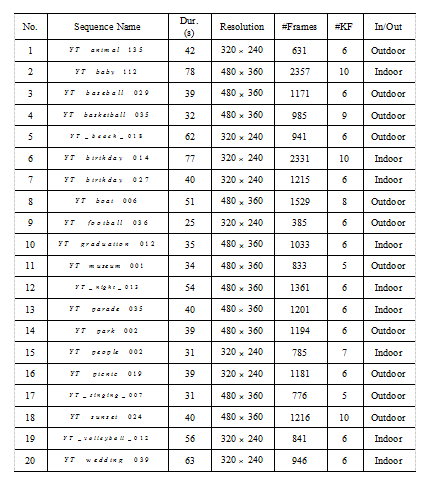
Table I
实验中的视频信息. 第三行列出了每个视频的时长;第五行列出了视频帧的总数;第六行列出了关键帧的个数。
V.实验结果
在这一小结,我们在一些消费类视频上做了性能评价。除此之外,也用我们的算法在移动机器人拍摄的视频上做了关键帧抽取。
A.消费类视频摘要
我们在Kodak数据集上做了实验评估。这个数据集被分为两个子类:Kodak和Youtube。每个子类都包含许多非结构化的消费视频。不幸的是,Kodak子类的原始视频没有公开。所以,我们选取20段有代表性的Youtube子类的视频序列来做评估。这些视频包含不同的主题,详细信息见表Table I。为了更好地去评价,我们请11位志愿者对所有序列做了关键帧标注。预先设定的关键帧数目不超过视频长度的1%并且最小最大值分别是10和5。标注的时候,根据文献[19]的建议,我们强制志愿者必须设定一些时间区间,标注出的关键帧必须在这些时间区间内。只有那些被大多数志愿者做标记的关键帧才认为是一致的,否则删掉。一个候选关键帧被认为是好匹配,只有在它位于志愿者设定的时间区间内。根据[22]中的建议,我们将分数设定为三个等级,0代表不匹配;1代表好匹配;0.5代表弱匹配。0.5被赋予那些不在标注区间中但和某个关键帧又有一些相似的候选关键帧。要注意的是,一个关键帧被匹配,不管是好匹配还是弱匹配,只能有一个候选关键帧。

五个方法进行了比较:(1) 均匀分布关键帧,通过在时间轴上均匀采样,产生与标注相同数量的关键帧。(2) K-MED方法用k-Mediod聚类产生与标注相同数量的关键帧。聚类中心被认为是关键帧。在实验中,k-Mediod算法运行了100次,取具有最小目标函数值的结果。(3) 文献[22]和[23]讨论了字典选择方法。我们用了文献[23]作者提供的源代码(SRMS)。(4) 不相似方法(DIS)[25]用了不相似性来实现并行稀疏编码。(5) 我们提出的结构化L2,1方法。前四种方法中,EKFS和K-MED是基线方法,SRMS和DIS是最新的方法。所有方法都用[22]中提供的特征。每一个视频帧的特征都是一个360维的向量包括颜色和文本信息。这样的设置能保证不同方法的公平比较。
Fig.2提供了在YT_animal_135视频上标注和五种算法比较的例子:ground-truth (第一行),ESKF (第二行),K-MED (第三行),SRMS (第四行),DIS (第五行),Proposed (第六行)。我们用不同颜色的框包围ground-truth关键帧。从第二行到第六行,与ground-truth相同颜色的实线框代表好匹配,虚线十字架代表弱匹配。从这幅图我们可以看到,ESKF方法得到两个好匹配(#128和#509),和两个弱匹配(#1和#255)。KMED得到了3个好匹配(#167, #324, #551),和一个弱匹配(#109)。用不相似性来选择关键帧的DIS方法,忽略了重构能力,只选择出两个关键帧(#76和#326)并且丢失了重要信息(比如帧405)。SRMS和本文的方法分别选出了4个和5个好的匹配。需要说明的是,SRMS方法的结果也在时间上均匀地分布而且没有出现非常接近的关键帧。原因是这个方法有一个后处理模块,如果有非常接近的帧,就会把多余的删掉。
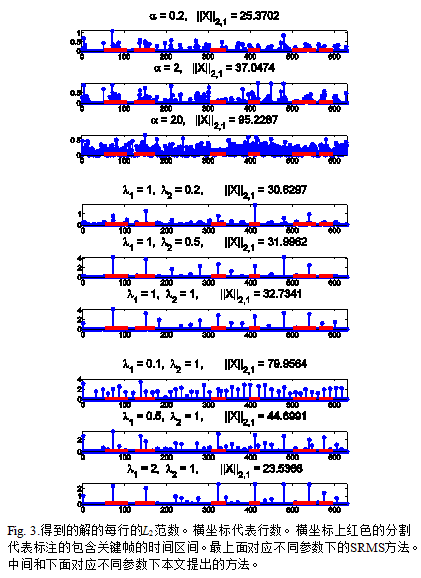
Fig.3给出了得到的解X每一行的L2范数。这样的图通常用来排序视频帧,选出关键帧。Fig.3最上面的部分给出了SMRS方法的结果,其中α分别为0.2, 2和20。需要说明的是,α是[23]提供源码中的正规化参数,一般设为[2,20]。Α越小,结果越稀疏。中间的部分给出了本文方法的结果,其中λ1 = 1,λ2分别为0.2, 0.5, 1。下面的部分也是本文方法的结果,其中λ1分别为0.5, 1, 2,λ2 = 1。从这个图中,我们可以看到本文方法的优势。通过SRMS方法得到的结果是非结构化的,而且需要一个精心设计的后处理模块。除此之外,随着α值的减小,系数向量变得越来越稀疏,但是哪个帧应该被选中依旧不明确(参考α = 0.2时的结果)。更糟的是,当α值比较小时,关键帧#414可能被淹没(见Fig.3的第一行)。在中间部分,随着λ2的减小,得到的结果会变得有一些密集,但是因为互抑制结构的引入,对关键帧选择没有太多的影响。除此之外,尽管本文的方法没有选中关键帧#580,观众依然能够容易地理解整个过程。由于人类理解和我们采取的特征向量之间存在着语义鸿沟,所以本文的方法没有选中帧#580。文献[19]中分析了类似的现象。
Fig.4给出了在视频序列YT_wedding_039上的结果。在这个视频上,ESKF得到了4个好匹配 (#190, #379, #757和#947)。K-MED得到了4个好匹配和一个弱匹配关键帧(#913),然而SRMS(见第四行)和DIS(见第五行)只得到两个好匹配。从最后一行,我们可以看出,我们的方法得到的关键帧有时候虽然不同,但却和人工标注的ground truth很接近。

Fig.5给出了每个视频序列的准确率。准确率被定义为匹配的分与Table I 中所示的ground-truth总数的比。[22]中用相同的方法做了关键帧选取的评价。如Fig.5所示,本文的方法对于大多数视频有更好的结果。为了更好地说明,Fig.6列出了不同视频用该方法选出的最优代表性的关键帧。
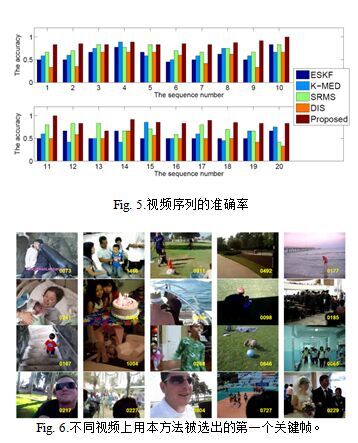
为了评价方法的参数敏感性,我们令公式(10)中的λ1和λ2从10?4到102变化,分别在数据集上运行我们的方法。准确率如Fig.7所示,我们可以看到最好的λ1和λ2都是出现在区间[0.1,1]。事实上,无论λ1或λ2太大都不能使重构误差变小,被选出的关键帧的表达能力也不能保证。另一方面,当λ1/λ2太大时,虽然能保证稀疏性,但却不能保证多样性,选出的帧有可能相距很近。对于λ1的不同选择,最好的结果往往发生在λ1/λ2接近1的时候。从敏感图中,我们可以得出结论,一个合理设计的多样性项实际上在抽取关键帧的过程中扮演着重要的角色。
为了定量分析,我们来评估是否得到的关键帧可以很好地重建整个视频片段。为了这个目的,我们基于所用的视觉特征定义一个保真度指数。严格来讲,这样的指数只能部分地反映选出的关键帧的保真度。对于一个N帧的视频,我们用以下的重构误差来定义保真度,
 (18)
(18)
其中表示长度为N的视频片段的特征,表示对应被选出的n个关键帧的子矩阵,X是非负系数矩阵。这个问题可以通过非负最小二乘优化容易地解决。

Fig.8给出了每一个视频片段的重构误差,K-MED有最好的结果,甚至比ground-truth的结果都好。这反映出低层次视觉特征与高层次人类理解的鸿沟。尽管SRMS和本文方法是基于相同的重构目标函数,SRMS的表现比本文的更差。主要原因是SRMS没有考虑多样性,所以如果只有一些帧被选中,重构性能就会变坏。除此之外,多余的后处理模块会破坏重构能力。本文的方法中,多样性被特地考虑,所以尽管只有一些帧被选中,他们也有充分的多样性,能够很好地重构整个视频序列。这些结果证实了多样性项的有效性。
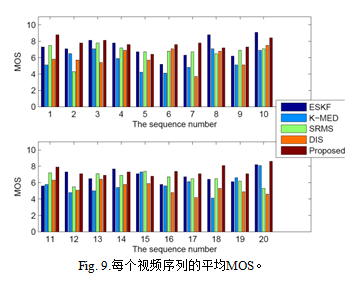
除了上面的评价,作者又请单独的用户观看视频片段,对每一个关键帧选择结果给出了区间[1,10]中的分数。为了反映用户主观的感觉,[29]也采用了相同的策略。Fig.9列出了每个视频片段的平均建议分数。我们可以看到,本文的方法要比SRMS和DIS表现得更好。一个重要的原因是本文的方法能得到更加多样性的结果,用户在看这些结果的时候感觉更好,ESKF也有好的结果。然后,它的表现很强地依赖于预先设定好的关键帧数。
B.机器人实验
提取关键帧对于机器人非常有用。例如,选出的关键帧位置可以用来当作关键位置在地面上标注出来。

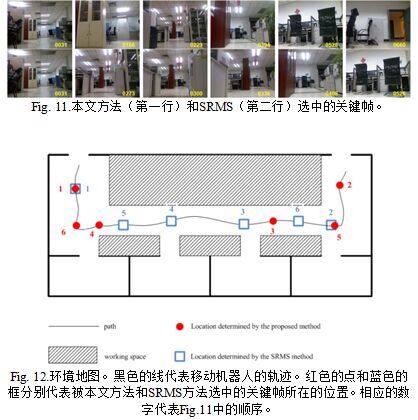
为了展示本文关键帧选取方法的性能,我们用Kinect相机收集了一段视频序列。我们在一个PowerBot机器人上进行了实验(见Fig.10)。这个机器人装备了几何和Kinect相机。在实验过程中,我们用一个操纵杆来控制机器人在一个预先设定好的室内轨迹上行走。机器人的速度被限制在0.6米每秒,图像序列的采集速度大约15Hz。采集到的视频帧序列连同他们的时间戳和空间位置一起存到一个文件当中以进行离线处理计算得到关键帧。
机器人首先进入入口,然后沿直线大约行走8米。然后,在一个拐角处左转90度,沿着走廊行走大约12米。最后,继续左转到达出口(大约7米)。整个过程由683帧组成。程序的输出是一个机器人环境的图片集合。Fig.11列除了通过SRMS和本文方法得到的最优代表性的6个关键帧。为了定量地评估关键帧选取方法,他们的空间位置在地图上投影了出来(见 Fig.12)。从中可以看出,我们的方法能帮助机器人找到更加多样性的关键帧。比如,SRMS选中了3个相同的图片帧(273, 300和336),都位于走廊上,却忽略了2个重要的位置:接近入口的拐角和接近出口的地点。这两个位置被本文的方法成功地检测到(见Fig.11第一行的帧166和660)。
VI.结论
这篇文章的目的是为给一段短视频提供一种有意义的表达建立一个自动算法。为此,我们建立了一个同事能刻画重建能力和多样性的结构化的L2,1优化模型。这个模型中加入了互抑制惩罚项来防止相似的视频帧被同时选中,所以,多样性被显式地促进。对于不同的互抑制项,本文有高度的灵活性。特别地,本文加入了一个直接的时间依赖惩罚。为了解决这样的优化模型,本文运用了迭代算法,优化的结果给出了排序好的帧列表。最后,我们用Youtube上的和室内移动机器人拍摄的视频来评价其性能。结果显示,我们的策略能帮助优化模型得到比其他当前工作更加多样化的关键帧。当前,互抑制矩阵已经被设计者预先设定好了。怎样自动通过实际视频的内容去学出这样的矩阵看起来更有趣。这样的问题是未来工作一个重要的主题。
参考文献
[1]S. Chen, J. Zhang, Y. Li, J. Zhang, A hierarchical model incorporating segmented regions and pixel descriptors for video background subtraction, IEEE Trans. on Industrial Informatics, vol.8, no.1, pp.118-127, 2012
[2]C. Cotsaces, N. Nikolaidis, I. Pitas, Video shot detection and condensed representation: A review, IEEE Signal Processing Magazine, vol.23, no.2, pp.28-37, 2010
[3]B. T. Truong, S. Venkatesh, Video abstraction: A systematic review and classification, ACM Trans. on Multimedia Computing, Communications and Applications, vol.3, no.1, pp.1-37, 2007
[4]D. Bruckner, C. Picus, R. Velik, W. Herzner, G. Zucker, Hierarchical semantic processing architecture for smart sensors in surveillance networks, IEEE Trans. on Industrial Informatics, vol.8, no.2, pp. 291-301, 2012
[5]T. Zhang, S. Liu, C. Xu, H. Lu, Mining semantic context information for intelligent video surveillance of traffic scenes, IEEE Trans. on Industrial Informatics, vol.9, no.1, pp.149-160, 2013
[6]X. Cao, B. Ning, P. Yan, X. Li, Selecting key poses on manifold for pairwise action recognition, IEEE Trans. on Industrial Informatics, vol.8, no.1, pp.168-177, 2012
[7]R. Hunger, Floating point operations in matrix-vector calculus, Techninal Report, Technische Universitat Munchen, Associate Institute for Signal Processing, 2007
[8]C. Yang, J. Peng, J. Fan, Image collection summarization via dictionary learning for sparse representation, in: Proc. of Computer Vision and Pattern Recognition(CVPR), pp.1122-1129, 2012
[9]A. Dame, E. Marchand, Using mutual information for appearance-based visual path following, Robotics and Autonomous Systems, vol.61, pp.259-270, 2013
[10]J. Tardif, Y. Pavlidis, K. Daniilidis, Monocular visual odometry in urban environments using an omnidirectional camera, in: Proc. of Int. Conf. on Intelligent Robots and Systems(IROS), pp.2531-2538, 2008
[11]P. Henry, M. Krainin, E. Herbst, X. Ren, D. Fox, RGB-D mapping: using depth cameras for dense 3D modeling of indoor environments, Int. J. of Robotics Research, pp.1-17, 2012
[12]F. Fraundorfer, D. Scaramuzza, Visual odometry, IEEE Robotics and Automation Magazine, pp.78-90, 2012
[13]G. Klein, D. Murray, Improving the agility of keyframe-based SLAM, in: Proc. of European Conf. on Computer Vision(ECCV), pp.802-815, 2008
[14]N. Snavely, S. M. Seitz, R. Szeliski, Skeletal graphs for efficient structure from motion, in: Proc. of Computer Vision and Pattern Recognition(CVPR), pp.1-8, 2008
[15]G. Klein, D. Murray, Parallel tracking and mapping for small AR workspaces, in: Proc. of Int. Symp. on Mixed and Augmented Reality(ISMAR), pp.225-234, 2007
[16]A. Girgensohn, J. Boreczky, Time-constrained key frame selection technique, in: Proc. of Int. Conf. on Multimedia Computing and Systems, pp.756-761, 1999
[17]Y. Fu, Y. Guo, Y. Zhu, F. Liu, C. Song, Z. H. Zhou, Multi-view video summarization, IEEE Trans. on Multimedia, pp.717-729, 2012
[18]F. Chen, C. Vleeschouwer, Formulating team-sport video summarization as a resource allocation problem, IEEE Trans. on Circuits Systems and Video Technology, vol.21, no.2, pp.193-205, 2011
[19]D. I. Kosmopoulos, A. S. Voulodimos, A. D. Doulamis, A system for multi-camera task recognition and summarization for structured environments, IEEE Trans. on Industrial Informatics, vol.9, no.1, pp.161-171, 2013
[20]J. Luo, C. Papin, K. Costello, Towards extracting semantically meaningful key frames from personal video clips: From humans to computers, IEEE Trans. on Circuits and Systems for Video Technology, vol.19, no.2, pp.289-301, 2009
[21]H. Cheng, Z. Liu, L. Yang, and X. Chen, Sparse representation and learning in visual recognition: theory and applications, Signal Processing, vol. 93, no.6, pp. 1408-1425, Jun. 2013.
[22]Y. Cong, J. Yuan, J. Luo, Towards scalable summarization of consumer videos via sparse dictionary selection, IEEE Trans. on Multimedia, vol.14, no.1, pp.66-75, 2012
[23]E. Elhamifar, G. Sapiro, R. Vidal, See all by looking at a few: Sparse modeling for finding representative objects, in: Proc. of Computer Vision and Pattern Recognition(CVPR), pp.1600-1607, 2012
[24]H. Cheng, Z. Liu, L. Hou, and J. Yang, Sparsity induced similarity and its applications, IEEE Transactions on Circuits and Systems for Video Technology, In press
[25]E. Elhamifar, G. Sapiro, R. Vidal, Finding exemplars from pairwise dissimilarities via simultaneous sparse recovery, in: Proc. of Advances in Neural Information Processing Systems (NIPS), pp.1-9, 2012
[26]F. Nie, H. Huang, X. Cai, C. Ding. Efficient and robust feature selection via joint l2,1-norms minimization, in: Proc. of Advances in Neural Information Processing Systems(NIPS), pp.1-9, 2010
[27]K. Gregor, A. Szlam, Y. LeCun, Structured sparse coding via lateral inhibition, in: Proc. of Advances in Neural Information Processing Systems(NIPS), pp.1-9, 2011
[28]J. Li, N. Allinson, Building recognition using local oriented features, IEEE Trans. on Industrial Informatics, vol.9, no.3, pp.1697-1704, 2013
[29]A. Sentinelli, L. Celetto, G. Marfia, M. Roccetti, Embedded key frame extraction in UGC scenarios, in: Proc. of Int. Conf. on Multimedia and Expo Workshops (ICMEW), 2013, pp.1-5, 2013












 恭喜你,发表成功!
恭喜你,发表成功!

 !
!